- As Spark 2 supports datasets which is the extension of RDDs, we can use these datasets to model into a Machine Learning Model and get the results back as recommendations
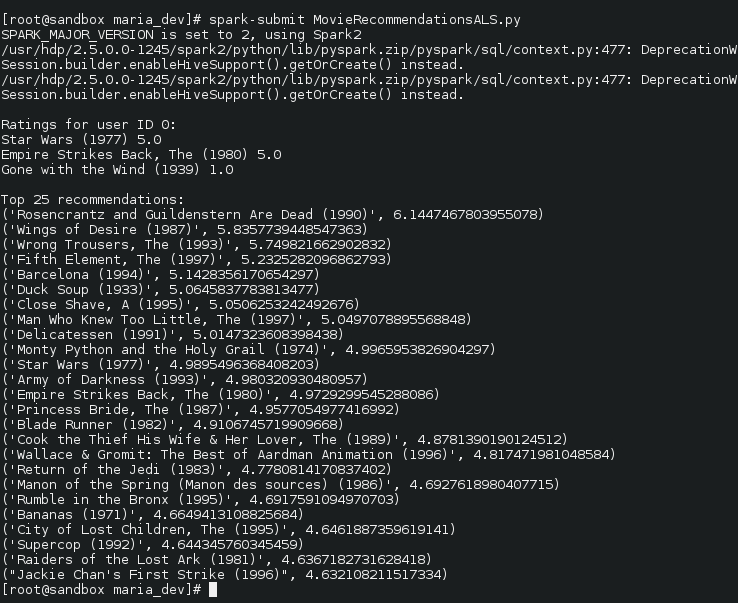
- To get into action lets make a little modifications to the u.data file – lets assume that there is a hypothetical userID ‘0’ which has rated ‘Starwars’ and ‘Empire Strikes’ as 5 but ‘Gone with the wind’ as 1.0.
-

these 3 rating added to the top of the u.data file and the file then uploaded back to HDFS location.
- Now upload the file to the HDFS location so that now we have a updated u.data file with these 3 extra ratings by userID 0
- Here is the code – https://s3.amazonaws.com/testbucket786786/MovieRecommendationsALS.py
- Here is the snapshot of the code with explanations
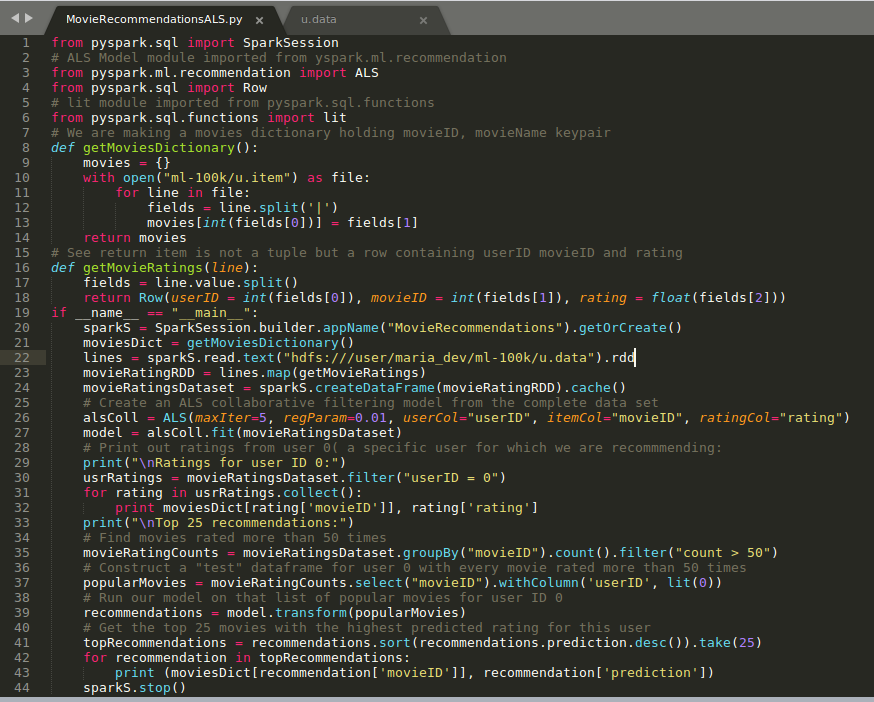
- This codes use a ALS Model for recomendations
- # Create an ALS collaborative filtering model from the complete data set
alsColl = ALS(maxIter=5, regParam=0.01, userCol=”userID”, itemCol=”movieID”, ratingCol=”rating”)
model = alsColl.fit(movieRatingsDataset) - and
- # Run our model on that list of popular movies for user ID 0
recommendations = model.transform(popularMovies) - Here are the results for the movie recommendations using machine learning in Spark 2…..Nice group of movie below….as recommendations ….