- Spark 2 extends the RDDs(Resilient Distributed Dataset) in terms of a “DataFrame”
- Dataframe contains Row Objects thus give you power to use Spark SQL and Spark Machine Learning etc
- It can process from any kind of relational or non-relational data source .
- You can use commands similar to SQL like Select, Group by , Order by, register your own functions :
- dataFrame.select(“fieldnames”) for projection
- dataFrame.select(“fieldnames”> 20) for filtering data
- dataFrame.groupby(“fieldnames”) for grouping and aggregating data
- dataFrame.rdd().map(mapfunc) for get the underneath RDD
- While running Spark 2 you have to use export SPARK_MAJOR_VERSION=2 to notify that you are using spark 2
- The code is here – https://s3.amazonaws.com/testbucket786786/PopularMoviesSpark2.py
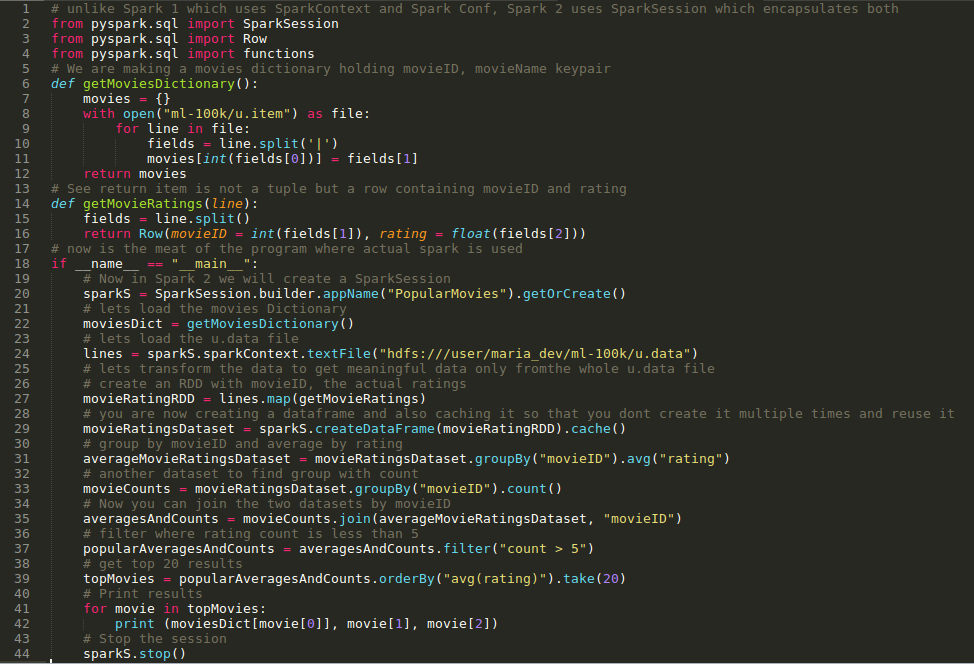 In the code above , you can see that a SparkSession is created and used trill programs ends and is stopped at the end.
In the code above , you can see that a SparkSession is created and used trill programs ends and is stopped at the end.- Creating a DataFrame was a simple command – sparkS.createDataFrame(movieRatingRDD).cache()
- The code used group by and avg commands to group by movieID and avg by rating
- It also uses to join 2 dataframes by movieID
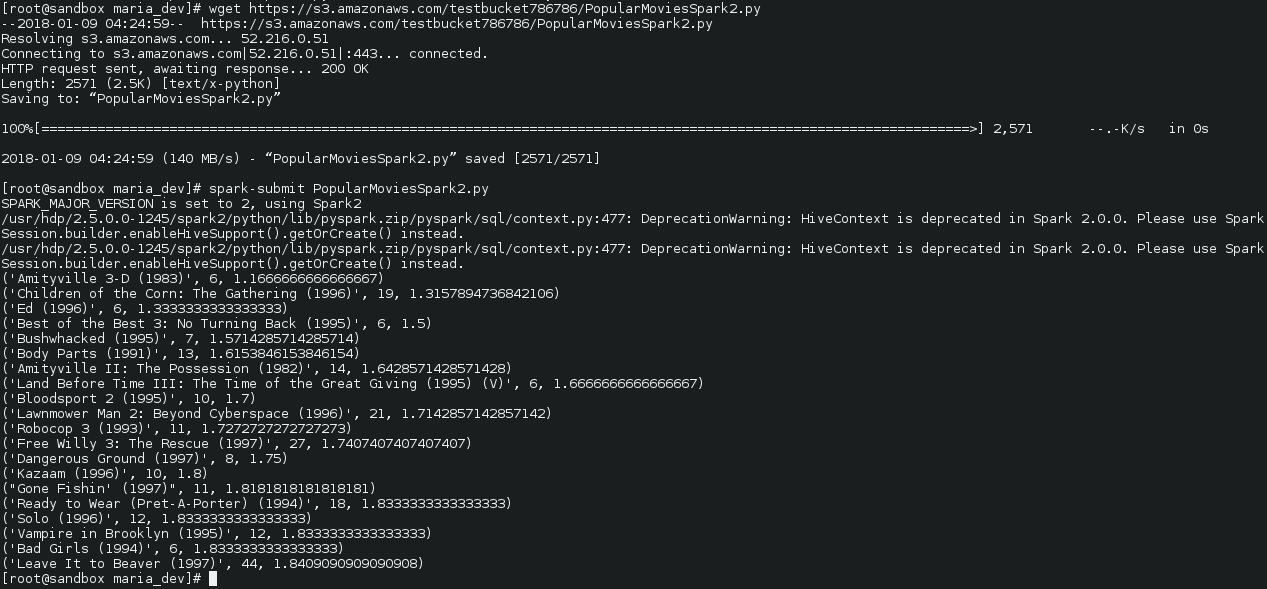
- Here is the end result ….AmityVille 3 D rated at an average 1.16 by 6 people is the worst of all movies
How to Process Data Using Spark 2
