- Apache Spark is super lightening fast Hadoop distributed processing service.
- Its execute in-memory that’s why it is the fastest of all processing engines
- it automatically analyses the best plan best on interrelation between differnet RDDs
- RDD means Resilient Distributed Dataset – meaning Spark ( using the SparkContext ) automatically takes care how the dataset will be stored and how much memory will be allocated to each cluster( using the Spark Configuration).
- The datasets are resilient because it can recover from issues or errors.
- Lets get into action with this script.
- Here is the link – https://s3.amazonaws.com/testbucket786786/PopularWorstMoviesSpark1.py
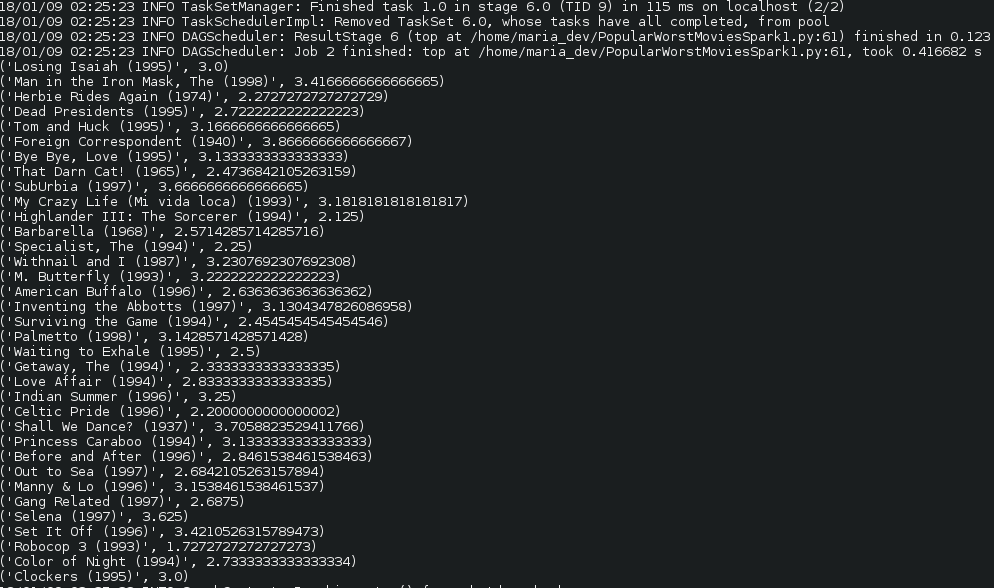
- We are trying to find the Popular Worst rated movies ….
See the snapshot of the code – (the explanations are commented)
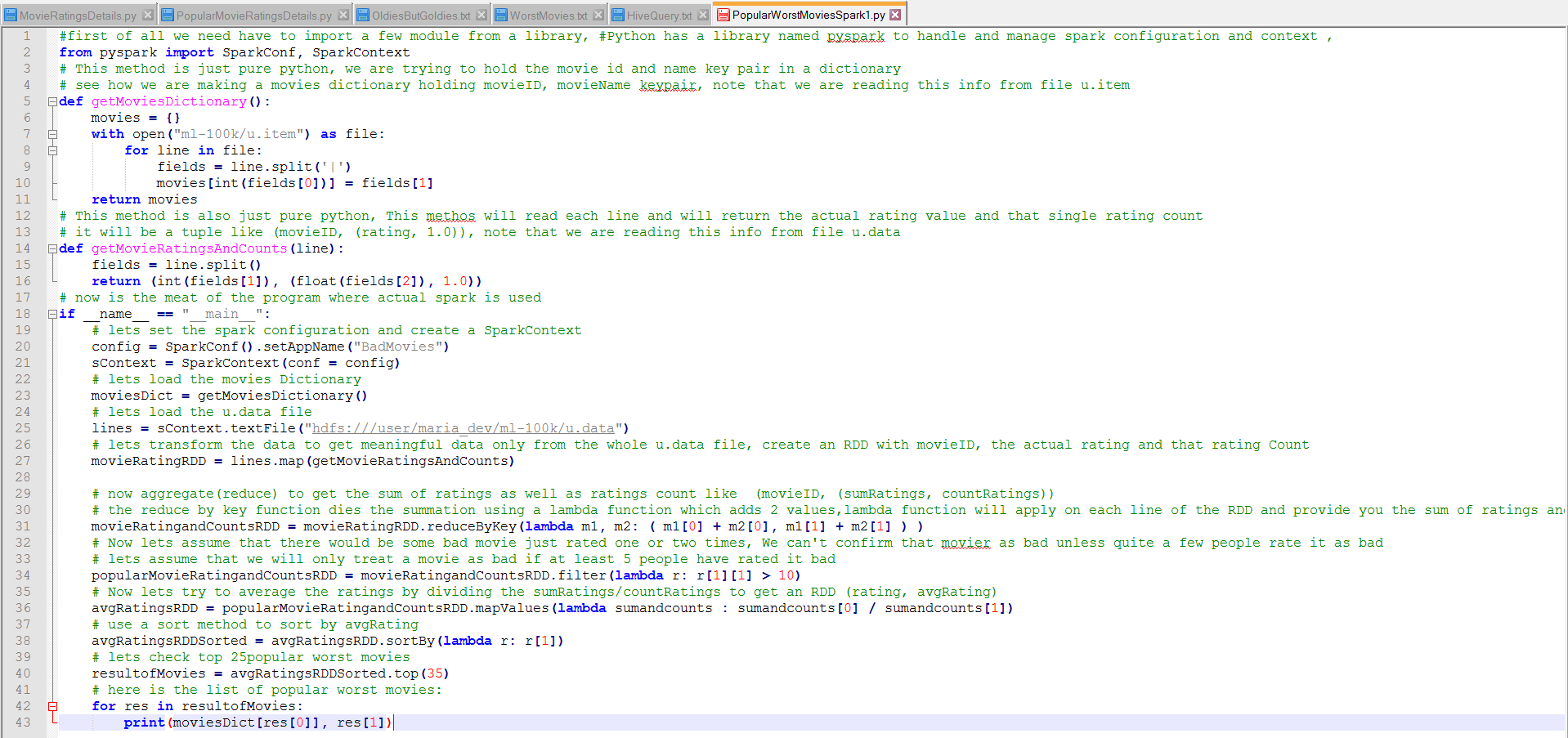
- To execute the above script – spark-submit PopularWorstMoviesSpark1.py
- Here is the result: Yay! here you go the worst popular movies.