As we know that the core of the Hadoop’s distributed processing system is MapReduce.
We can use on the top technologies like Hive, Pig, Spark, TEZ etc to process the data.
But you can directly write scripts in Python or Java or any supported language and execute them directly .
I will use Python to execute movie data-set directly in MapReduce.
There are some prerequisites to run Python with MapReduce as you need to install pip, MapReduce streaming module etc.
Also if you are using an old version of HortonWorks Sandbox then you might need to clean up sandbox.repo file in /etc/yum.repos.d ….Lets do it step by step
SSH into the sandbox using putty or any other compatible SSH tool using ‘maria_dev’ user id and password and 2222 as port
Install Prerequisites(setup sudo privileges by executing sudo su –):
Install pip: yum -y install python-pip
If errors in installation then type this(move sandbox.repo to tmp folder for time being and try re-installing pip againas above command ) : mv /etc/yum.repos.d/sandbox.repo /tmp
Install mrjob(installing 0.5.11 version due to old version of Hortonworks sandbox, if you are using 2.6.3 and above then you might not have any issues) : pip install mrjob==0.5.11
Install nano editor – yum -y install nano
logout from sudo privileges – exit
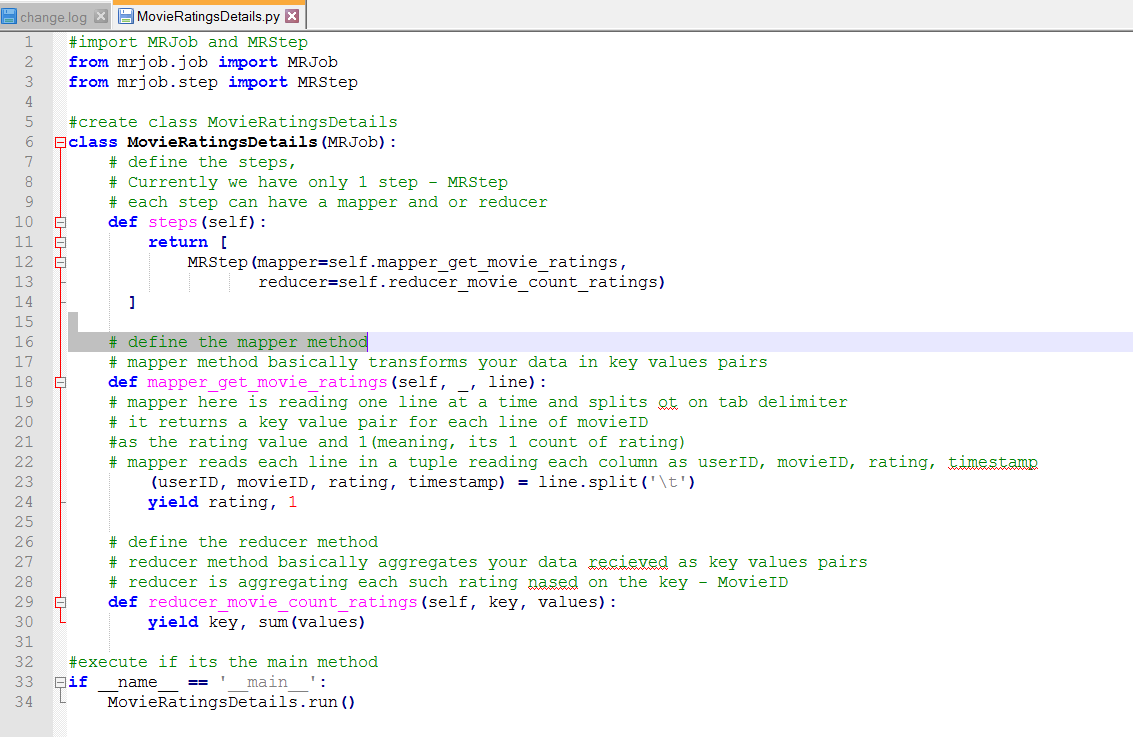
Either open nano and write the script or download it from here – wgethttps://s3.amazonaws.com/testbucket786786/MovieRatingsDetails.py
Open MovieRatingsDetails.py = nano MovieRatingsDetails.py
Explanation of each step is provided as green comments
Now you can run this Python script locally to test if there are no errors then you can run it under hadoop.
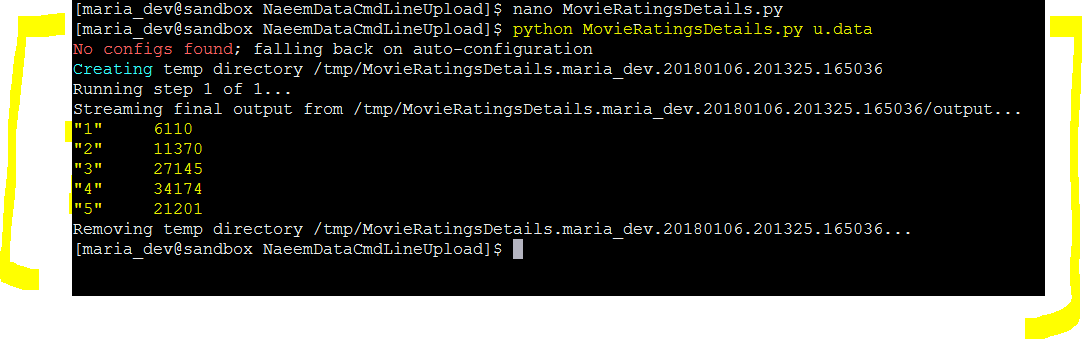
Running Locally(u.data is file name you are passing to the script) : python MovieRatingsDetails.py u.data
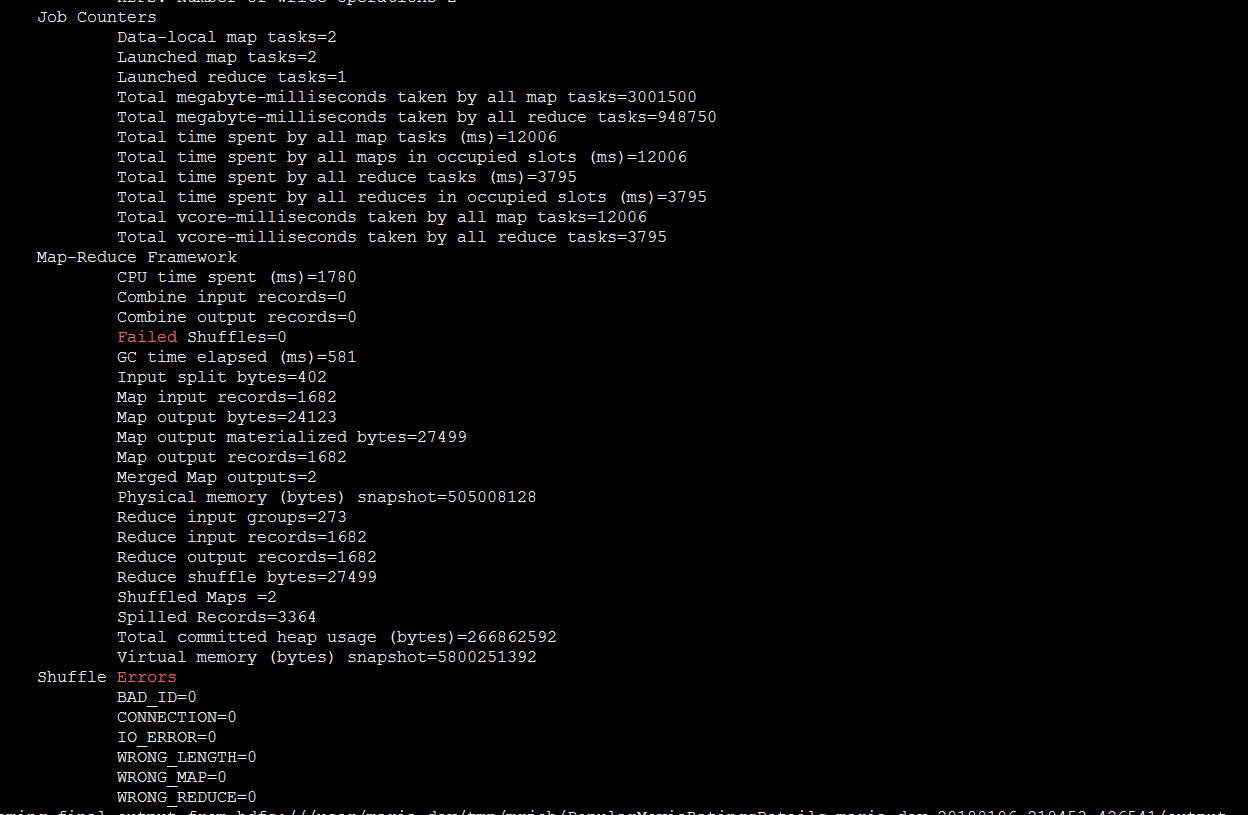
Success – you are seeing the ratings and count of ratings…34174 movies have been rated as 4 Now lets use a similar script to get the rating count of each movie(Most Popular Movies) – link here – https://s3.amazonaws.com/testbucket786786/PopularMovieRatingsDetails.py
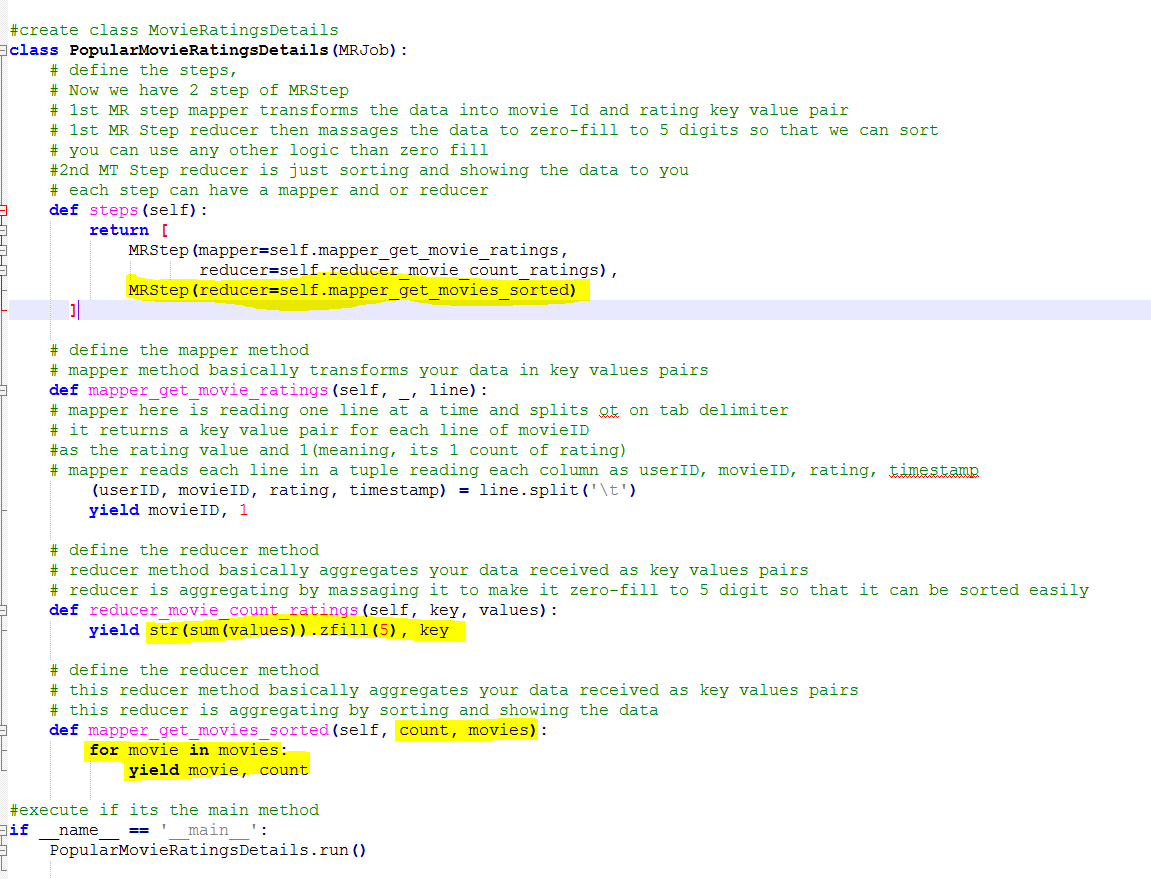
This script has 2 MRStep and result of 1st reducer goes to 2nd reducer for sorting the data
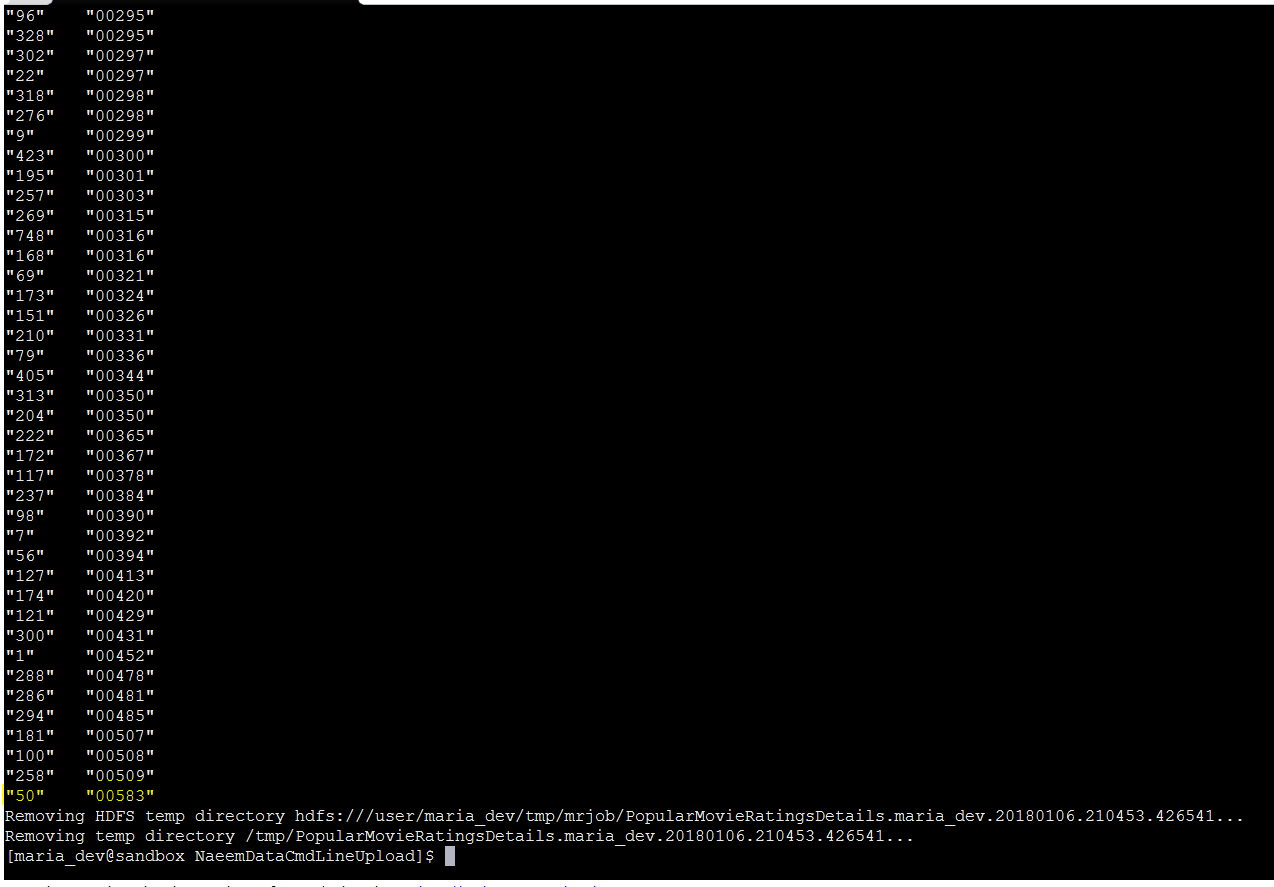
Lets execute this – python PopularMovieRatingsDetails.py u.data
There you go movie Id ’50’ is most popular and ‘1122’ is least popular.
To execute these script in Hadoop you have to specify a switch –r Hadoop and its hadoop streaming jar file
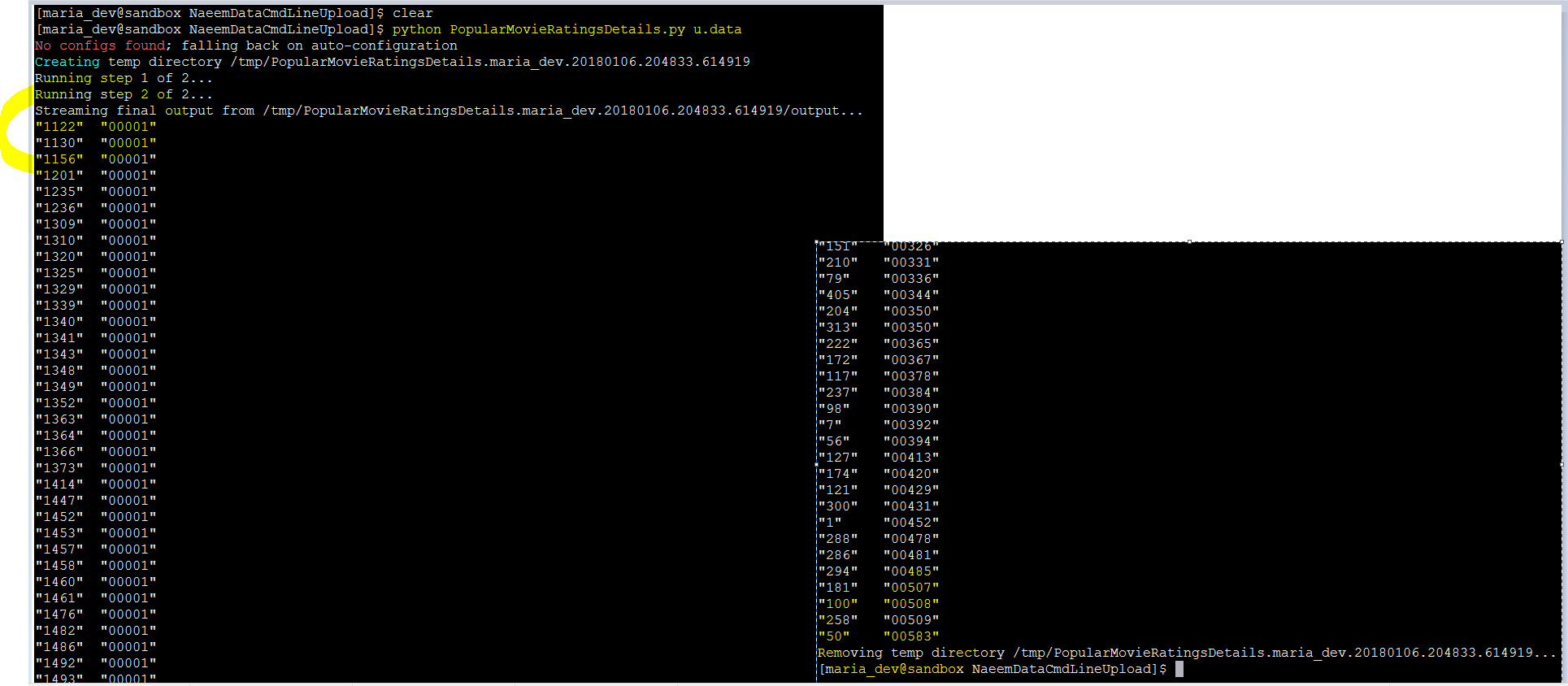
 There you go – the results – by directly executing a python script in MapReduce
There you go – the results – by directly executing a python script in MapReduce