
- As we know that HDFS is the distributed storage system of Hadoop. Similarly MapReduce is the core processing engine.
- Recently TEZ is also becoming a lot popular as it is much faster than MapReduce. the reason for its speed is its nature of interpreting the relationship between mapping, sorting, shuffling, sorting and it creates a execution plan based on the interpretation.
- Pig sits on the top of either MapReduce or TEZ and uses very nicely structured language called as ‘Pig Latin’ which uses a syntax quite similar to SQL.
- Lets try to process these 2 things using Pig on the top of MapReduce/TEZ
- Top Rated Oldest Movies – those oldies goldies movies – top rated means 4.0 and above on scale of 5.0
- Max Rated Worst movies – those movies which are worst rated but have got maximum ratings by users that they are worst – lol – Worst rated means 2.0 and below ratings.
- Okay, so login to Ambari Dashboard and open “Pig View” as below:
-
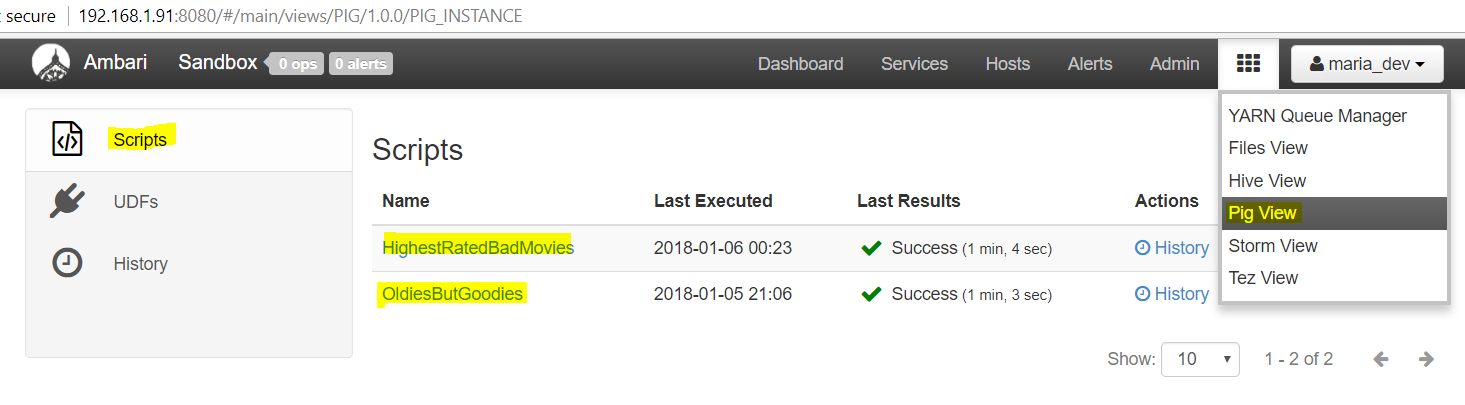
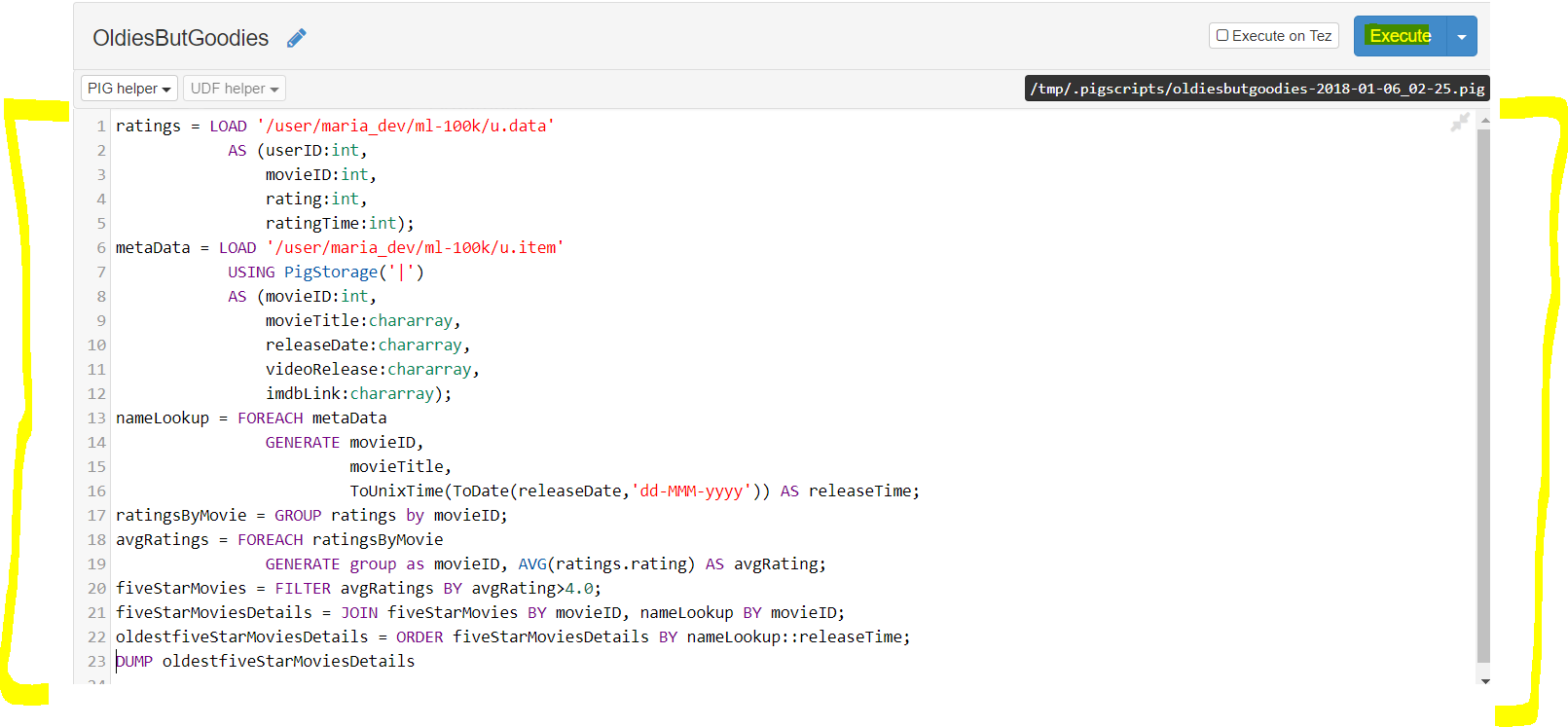
Click ‘Pig View’ and then on ‘New script’ - Now write the following script on the script editor window and Execute once using TEZ checkbox unchecked and then with TEZ checkbox checked and see the difference in speed of execution.
- Here is the link , you can download the script – https://s3.amazonaws.com/testbucket786786/OldiesButGoldies.txt
-
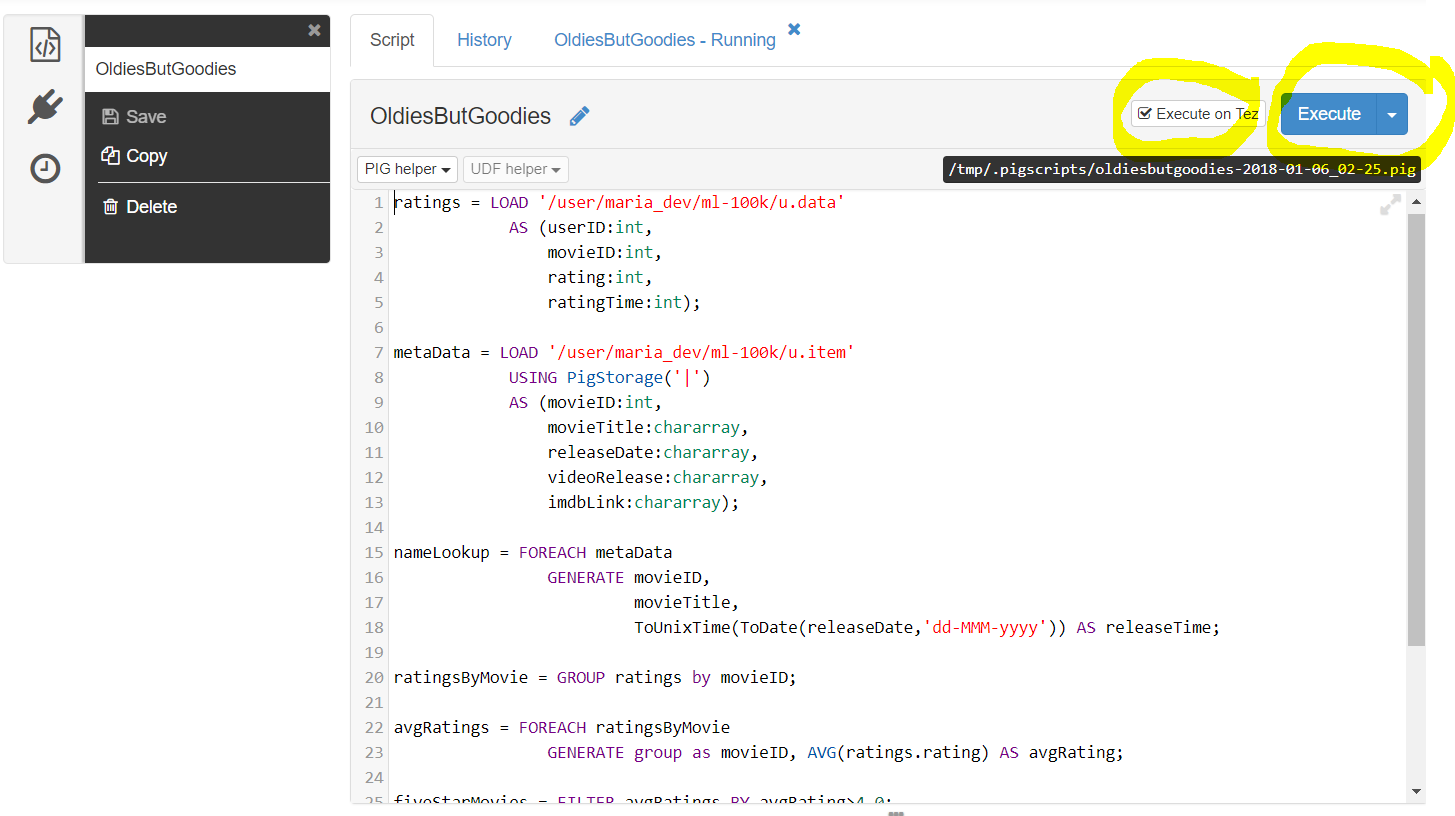
Checking “Execute with TEZ will use TEZ else MapReduce -
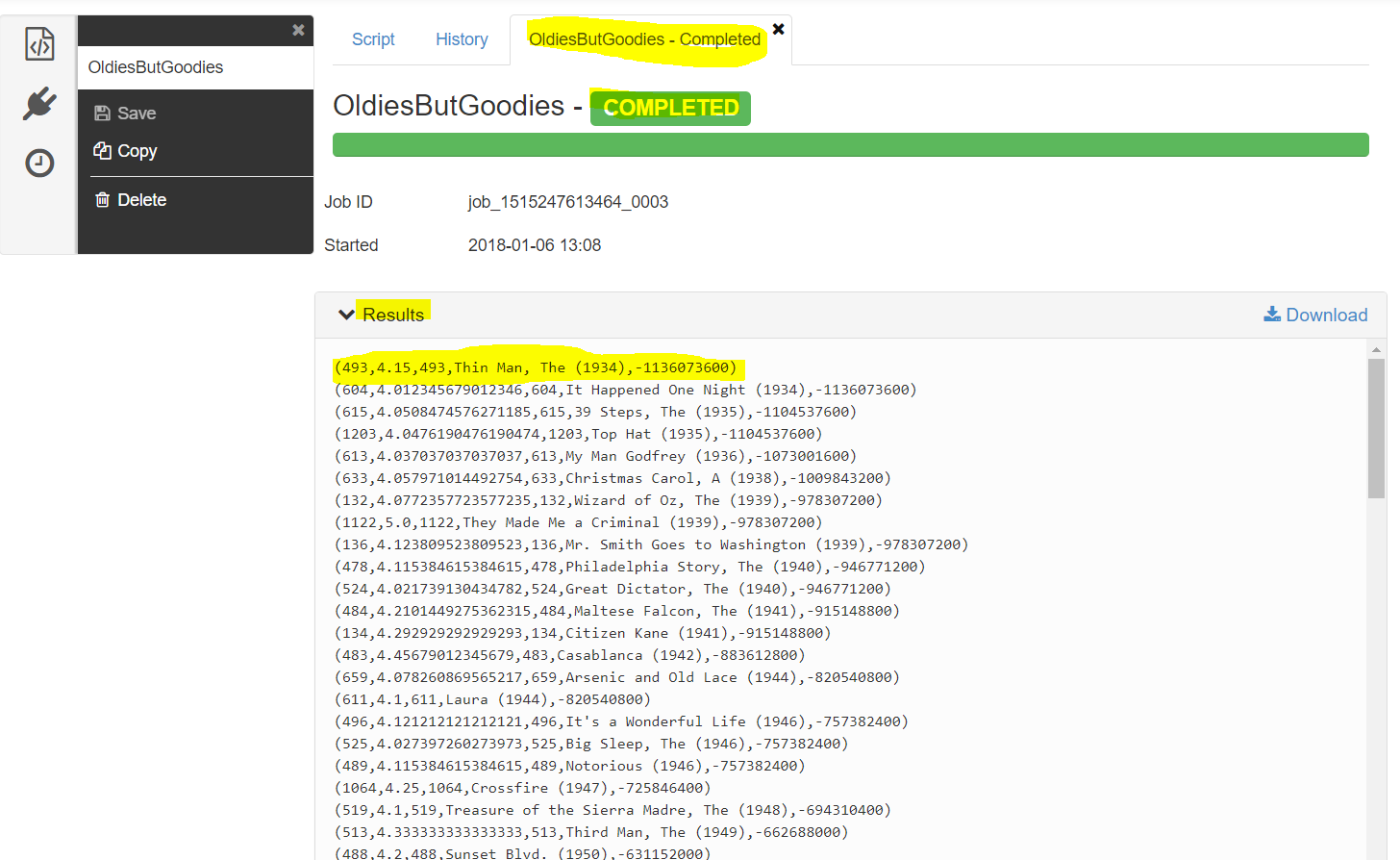
Result – The Thin Man 1934 is highest rated oldy ….another big data analysis…lol - Pig with TEZ is getting hotter these days due to its sheer speed.
- Now lets interpret the Pig Latin script
# PIG uses relations to process data# PIG uses relations to process data # Lets create a relation ‘ratings’ using the LOAD command to load the file from given path, # Specify column names and data types# By default the delimiter id TAB so we are good ratings = LOAD ‘/user/maria_dev/ml-100k/u.data’ AS (userID:int, movieID:int, rating:int, ratingTime:int);
# Lets create another relation ‘metaData’ using the LOAD command to load the file from given path, # Specify column names and data types # This file has a pipe delimiter so we have to use another command to specify the delimiter – USING PigStorage(‘|’)
metaData = LOAD ‘/user/maria_dev/ml-100k/u.item’ USING PigStorage(‘|’) AS (movieID:int, movieTitle:chararray, releaseDate:chararray, videoRelease:chararray, imdbLink:chararray); # Now lets do some transformation to make the release date in proper format # use ToUnixTime and ToDate function to converts date strings to dates # To create another relation from an exisitng relation, use command – ForEach relationname GENERATE # Generate command generates a new relation from exisitng one nameLookup = FOREACH metaData GENERATE movieID, movieTitle, ToUnixTime(ToDate(releaseDate,’dd-MMM-yyyy’)) AS releaseTime;
#now lets group the movies by movieId ratingsByMovie = GROUP ratings by movieID;
#now lets group the relation by average of the ratings #use AVG command to calculate average # and ForEach relationname GENERATE to generate a new relation avgRatings = FOREACH ratingsByMovie GENERATE group as movieID, AVG(ratings.rating) AS avgRating;
# now filter (FILTER command) movies with ratings 4.0 and above fiveStarMovies = FILTER avgRatings BY avgRating>4.0;
#now join the filtered relation with the movies metadata relation fiveStarMoviesDetails = JOIN fiveStarMovies BY movieID, nameLookup BY movieID;
#now ORDER by release date –the oldest movies will be on top with ratings 4 and above oldestfiveStarMoviesDetails = ORDER fiveStarMoviesDetails BY nameLookup::releaseTime;
# dump the relation to show the data(in prod world you will write the data into a file) DUMP oldestfiveStarMoviesDetails
- To find worst rated movies with maximum ratings you have yo change the above code at 2 places – filter woth rating less than equal to 2.0 and order by ratingcount descending
- Here is the link – https://s3.amazonaws.com/testbucket786786/WorstMovies.txt
-
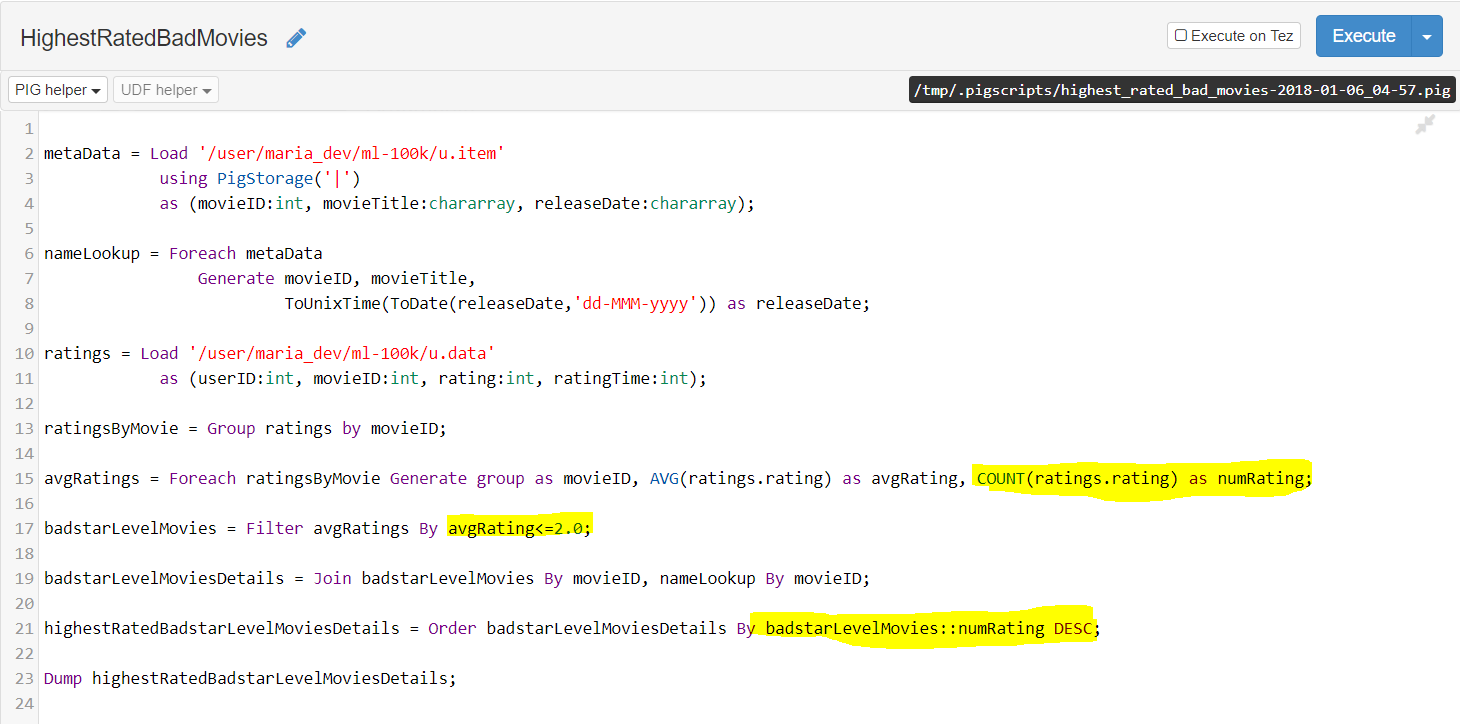
filter only those movies which are bad(rating 2.0 or below…while grouping add one more column for count of ratings and while ordering use this numofratings descending as the order by column 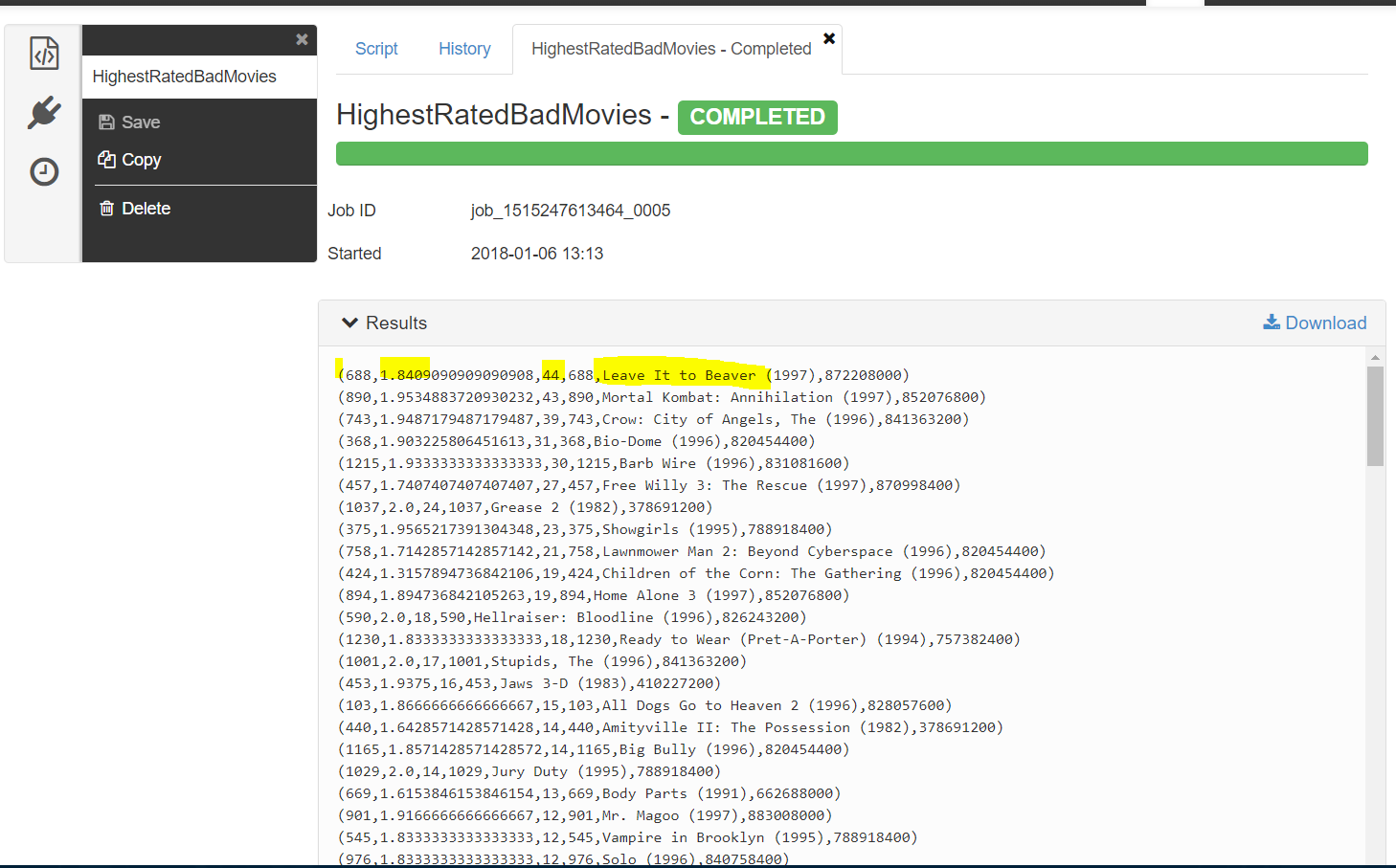
- Hurray you have now used PIG latin to get the old good movies as well as worst movies