
- The Problem:
- As a part of analysis of similar movie ratings, we would be using lot of RDD techniques and an algorithm Collaborative filtering to arrive at recommending similar movies to a customer
- join() – we will use join method to kind of make a ‘Cartesian Join’ to get each combination of a movie pair
- persist() or cache() – the later is caching in memory, the former is caching additionally to persistent storage media so that your cached data is not lost even if the executor goes down for a while
- Cosine based Algorithm to find movie similarities
- The Strategy:
- Get the movies data first and store it
- Get the ratings data next and store it
- Do a Cartesian join to get each combination of the movie pair to get an RDD like userID => ((movieID, rating), (movieID, rating))
- Strip duplicate movie key pairs
- make (movie1, movie2) as new key like (movie1, movie2) => (rating1, rating2)
- collect all ratings for each movie pair and group by key to find similarity like (movie1, movie2) = > (rating1, rating2), (rating1, rating2)
- apply the Cosine simialrity algorithm
- persist above data to the storage
- filter movie based on hypothetical condition for a good similar movies based on parThreshold, occurThreshold and sort by quality
- Display results
- The Code (with 100K data rows):
- Download Link –https://testbucket786786.s3.amazonaws.com/spark/sparkSimilarMovies100k.py
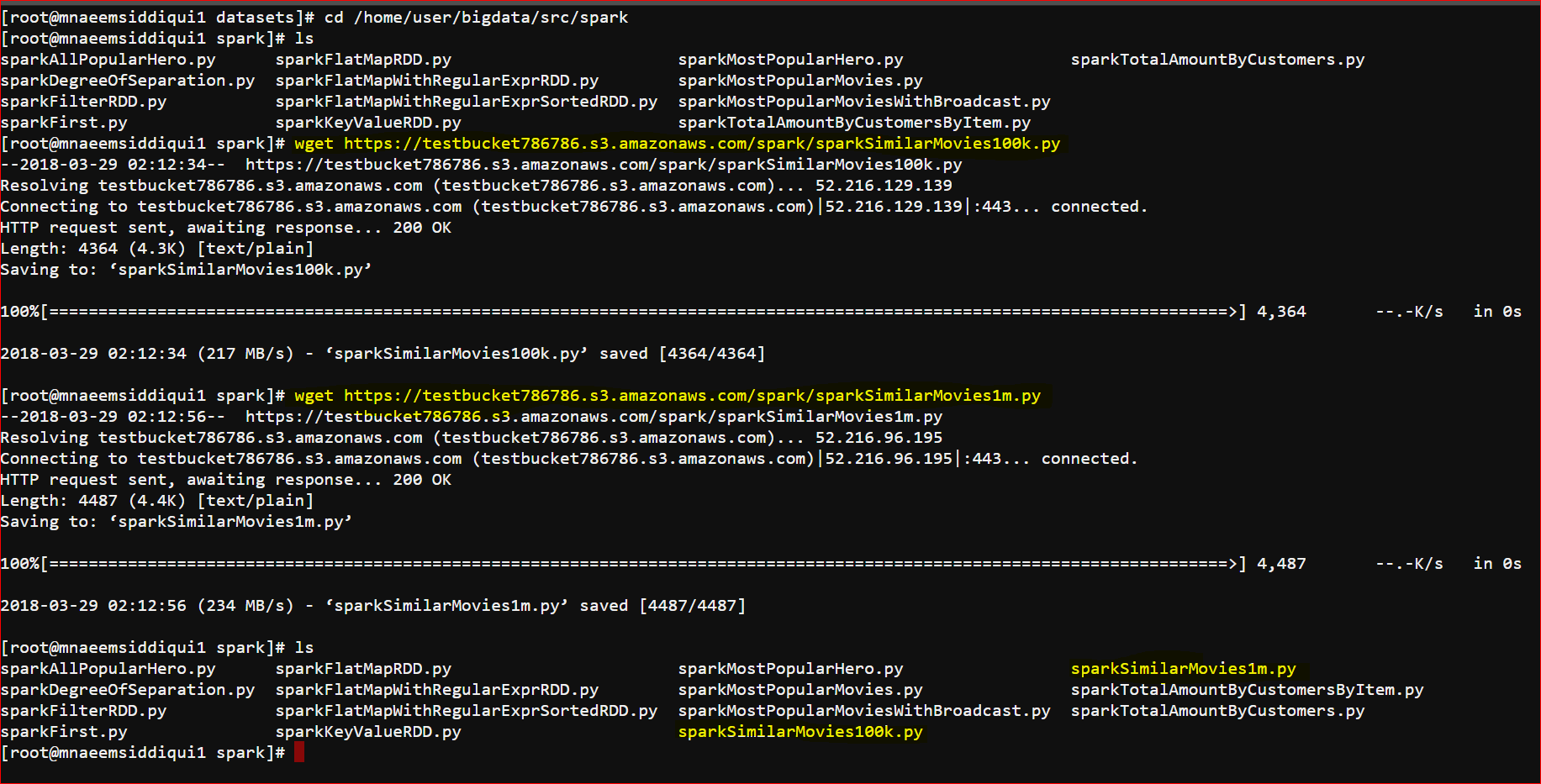
- The code:
-
# How to execute : spark-submit sparkSimilarMovies100k.py 50 # Import sys, SparkConf, SparkContext and sqrt
import sys
from pyspark import SparkConf, SparkContext
from math import sqrt # Python function for getting movie data as dict of (movie ID : Movie Title)
def getMovieData():
movieData = {}
with open(“/home/user/bigdata/datasets/ml-100k/u.item”) as fl:
for ln in fl:
fields = ln.split(“|”)
movieData[int(fields[0])] = fields[1]
return movieData # Python function for getting movie pairs from ratings
def getPairs( usersRatings ):
ratings = usersRatings[1]
(movie1, rating1) = ratings[0]
(movie2, rating2) = ratings[1]
return ((movie1, movie2), (rating1, rating2)) # Python function for striping similar movies ratings from ratings
def stripDuplicates( usersRatings ):
ratings = usersRatings[1]
(movie1, rating1) = ratings[0]
(movie2, rating2) = ratings[1]
return movie1 < movie2 # Python function for computing Similarity between movies
def computeCosineMoviesSimilarity(ratingPairs):
numPairs = 0
sum_xx = sum_yy = sum_xy = 0
for ratingX, ratingY in ratingPairs:
sum_xx += ratingX * ratingX
sum_yy += ratingY * ratingY
sum_xy += ratingX * ratingY
numPairs += 1 numerator = sum_xy
denominator = sqrt(sum_xx) * sqrt(sum_yy) score = 0
if (denominator):
score = (numerator / (float(denominator))) return (score, numPairs) # Setup SparkConf and SparkContext with new way to use all cores of the cluster – local[*]
sConf = SparkConf().setMaster(“local[*]”).setAppName(“SimilarMoviesApp”)
sContext = SparkContext(conf = sConf) # Get the movies data first
print(“\nGetting movies from movied data…”)
movieDict = getMovieData() # Get the rating data file, then Map ratings as user ID => movie ID, rating key pair
file = sContext.textFile(“/home/user/bigdata/datasets/ml-100k/u.data”)
ratingsData = file.map(lambda ln: ln.split()).map(lambda ln: (int(ln[0]), (int(ln[1]), float(ln[2])))) # Now do a cartesian join to get each combination of the movie pair to get an RDD like userID => ((movieID, rating), (movieID, rating))
joinedRatingsData = ratingsData.join(ratingsData) # strip duplicate pairs
uniqueJoinedRatingsData = joinedRatingsData.filter(stripDuplicates) # Now make (movie1, movie2) as new key like (movie1, movie2) => (rating1, rating2)
moviePairsData = uniqueJoinedRatingsData.map(getPairs) # Now collect all ratings for each movie pair and group by key to find similarity like (movie1, movie2) = > (rating1, rating2), (rating1, rating2) …
moviePairRatingsData = moviePairsData.groupByKey() # Now apply the Cosine simialrity algorithm.
moviePairSimilaritiesData = moviePairRatingsData.mapValues(computeCosineMoviesSimilarity).persist() # Now persist data on the storage, else use .cache() on above line
moviePairSimilaritiesData.sortByKey()
moviePairSimilaritiesData.saveAsTextFile(“sim-movies”) # Now extract the best similar movies
if (len(sys.argv) > 1): # hypothetical condition for a good similar movie based on parThreshold, occurThreshold
parThreshold = 0.97
occurThreshold = 50 # get the input from command line
movieID = int(sys.argv[1]) # filter the movies based parThreshold, occurThreshold for the movie pair
filteredResultsData = moviePairSimilaritiesData.filter(lambda pairSim: \
(pairSim[0][0] == movieID or pairSim[0][1] == movieID) \
and pairSim[1][0] > parThreshold and pairSim[1][1] > occurThreshold) # Sort by quality score.
resultsData = filteredResultsData.map(lambda pairSim: (pairSim[1], pairSim[0])).sortByKey(ascending = False).take(25) print(“Top 25 similar movies for ” + movieDict[movieID])
for result in resultsData:
(simlr, pair) = result
# Display the similarity results
similarMovieID = pair[0]
if (similarMovieID == movieID):
similarMovieID = pair[1]
print(movieDict[similarMovieID] + “\tscore: ” + str(simlr[0]) + “\tstrength: ” + str(simlr[1]))
-
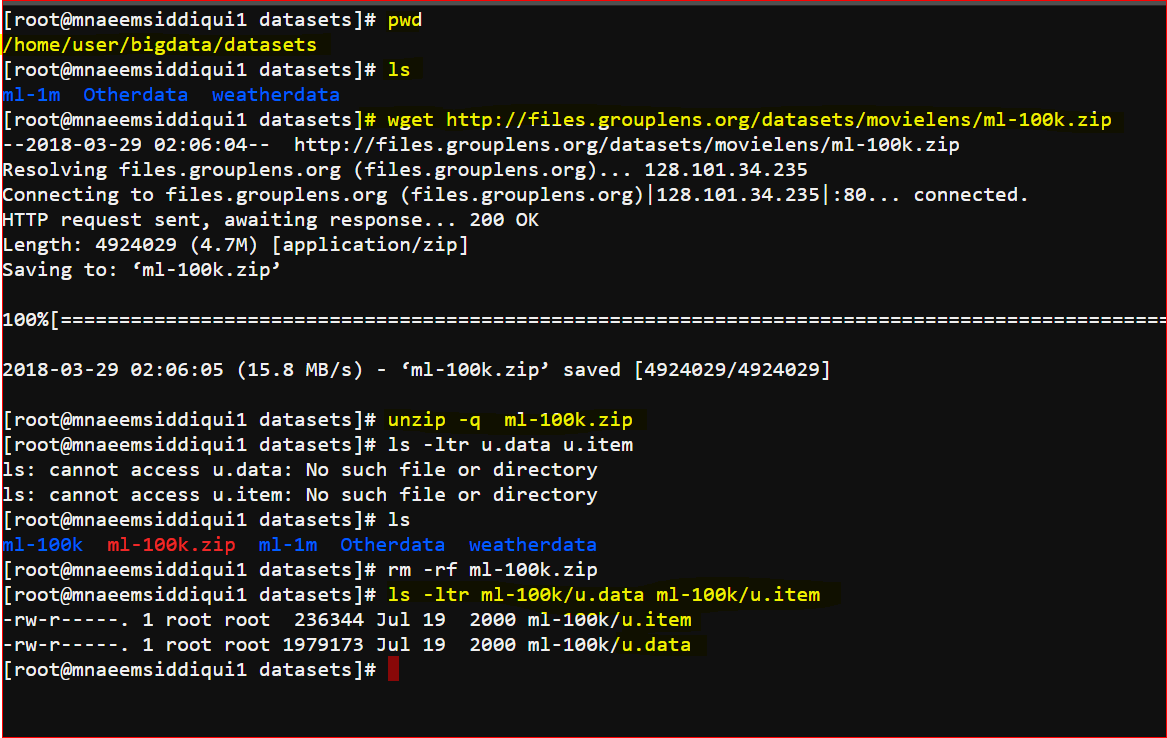
- Download the 100K data-set from Movielens website – http://files.grouplens.org/datasets/movielens/ml-100k.zip
- Unzip the contents and store in folder – /home/user/bigdata/datasets/ml-100k
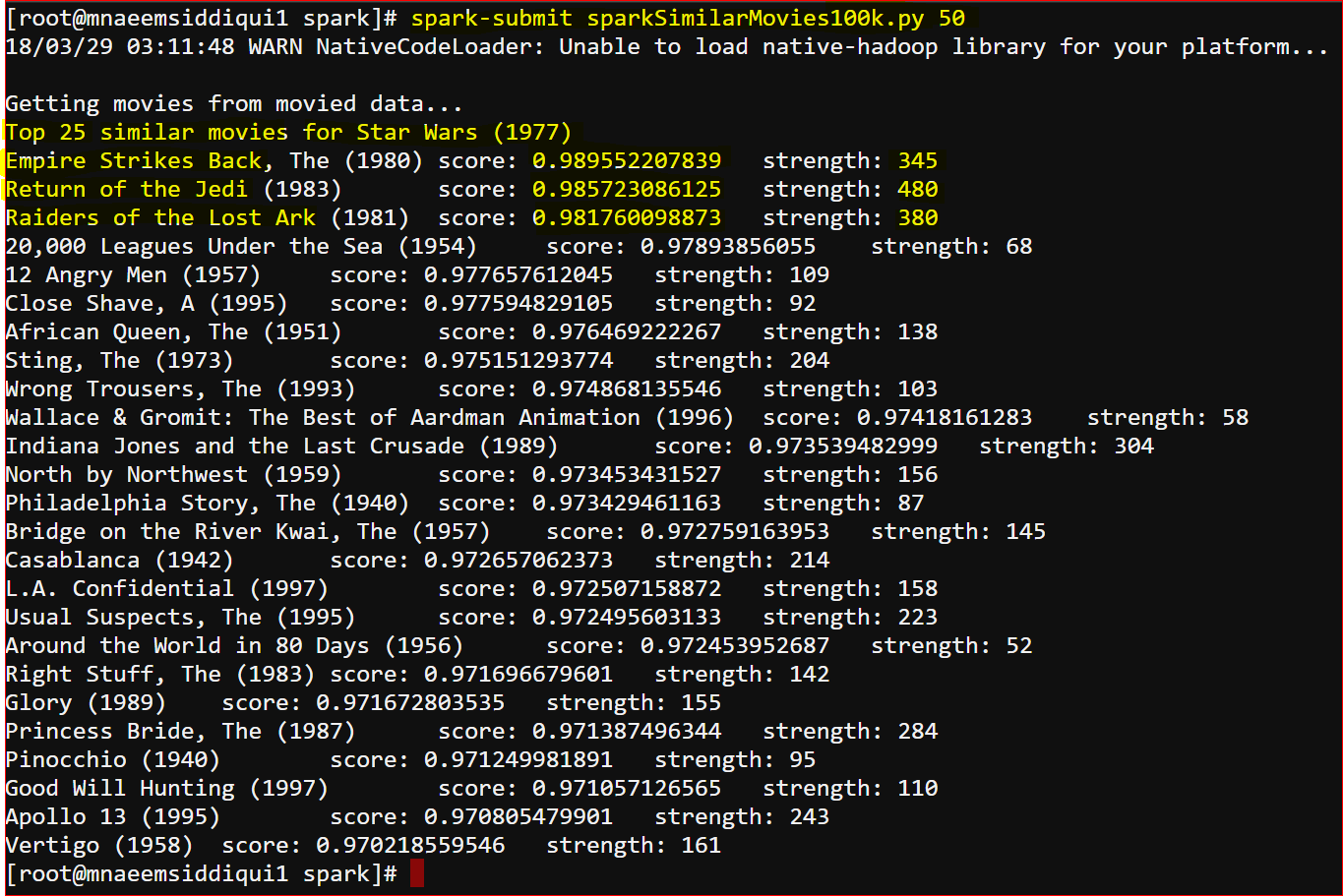
- The Output:
- Please see the output below:
- The Code (with 1 million data rows):
- Please note that this can be run on Amazon EMR too.
- You need to have an Amazon AWS account
- Click on EMR service and spin up a cluster say e.g. 1 master and 4 nodes
- In the configuration page it will ask for number of master and nodes, size of servers s3.xlarge will be good enough, the key and set of other things like if you want to only add spark or other applications too.
- Never forget to terminate the cluster until and because it will cost lot of money
- In the 1 million python script while creating the sparkContext use
- sConf = SparkConf()
- e.g. do not create any master etc as we will use cluster
- also you need to change paths of the movies and rating files to s3 paths like this( you have to upload these files in s3 bucket
- s3n.amazonaws.com/spark/data/ml-1m/movies.dat
- s3n.amazonaws.com/spark/data/ml-1m/ratings.dat
- To run first login to the cluster master node
- copy the script and the data(you can store data on s3)
- s3 cp s3n.amazonaws.com/spark/data/ml-1m/movies.dat ./
- s3 cp s3n.amazonaws.com/spark/data/ml-1m/ratings.dat ./
- s3 cp s3n.amazonaws.com/spark/sparkSimiarlMovies1m.py ./
- Now execute – spark-submit –executor-memory 1g sparkSimiarlMovies1m.py 260
- copy the script and the data(you can store data on s3)
- Download Link — https://testbucket786786.s3.amazonaws.com/spark/sparkSimilarMovies1m.py
- The code –
-
# How to execute : spark-submit –executor-memory 1g sparkSimilarMovies1m.py 50 # Import sys, SparkConf, SparkContext and sqrt
import sys
from pyspark import SparkConf, SparkContext
from math import sqrt # Python function for getting movie data as dict of (movie ID : Movie Title)
def getMovieData():
movieData = {}
with open(“/home/user/bigdata/datasets/ml-1m/movies.dat”) as fl:
for ln in fl:
fields = ln.split(“::”)
movieData[int(fields[0])] = fields[1]
return movieData # Python function for getting movie pairs from ratings
def getPairs( usersRatings ):
ratings = usersRatings[1]
(movie1, rating1) = ratings[0]
(movie2, rating2) = ratings[1]
return ((movie1, movie2), (rating1, rating2)) # Python function for striping similar movies ratings from ratings
def stripDuplicates( usersRatings ):
ratings = usersRatings[1]
(movie1, rating1) = ratings[0]
(movie2, rating2) = ratings[1]
return movie1 < movie2 # Python function for computing Similarity between movies
def computeCosineMoviesSimilarity(ratingPairs):
numPairs = 0
sum_xx = sum_yy = sum_xy = 0
for ratingX, ratingY in ratingPairs:
sum_xx += ratingX * ratingX
sum_yy += ratingY * ratingY
sum_xy += ratingX * ratingY
numPairs += 1 numerator = sum_xy
denominator = sqrt(sum_xx) * sqrt(sum_yy) score = 0
if (denominator):
score = (numerator / (float(denominator))) return (score, numPairs) # Setup SparkConf and SparkContext with new way to use all cores of the cluster – local[*]
sConf = SparkConf().setMaster(“local[*]”).setAppName(“SimilarMoviesApp”)
sContext = SparkContext(conf = sConf) # Get the movies data first
print(“\nGetting movies from movied data…”)
movieDict = getMovieData() # Get the rating data file, then Map ratings as user ID => movie ID, rating key pair
file = sContext.textFile(“/home/user/bigdata/datasets/ml-1m/ratings.dat”)
ratingsData = file.map(lambda ln: ln.split(“::”)).map(lambda ln: (int(ln[0]), (int(ln[1]), float(ln[2])))) # Now do a cartesian join to get each combination of the movie pair to get an RDD like userID => ((movieID, rating), (movieID, rating))
ratingsDataPartitioned = ratingsData.partitionBy(100)
joinedRatingsData = ratingsDataPartitioned.join(ratingsDataPartitioned) # strip duplicate pairs
uniqueJoinedRatingsData = joinedRatingsData.filter(stripDuplicates) # Now make (movie1, movie2) as new key like (movie1, movie2) => (rating1, rating2)
moviePairsData = uniqueJoinedRatingsData.map(getPairs).partitionBy(100) # Now collect all ratings for each movie pair and group by key to find similarity like (movie1, movie2) = > (rating1, rating2), (rating1, rating2) …
moviePairRatingsData = moviePairsData.groupByKey() # Now apply the Cosine simialrity algorithm.
moviePairSimilaritiesData = moviePairRatingsData.mapValues(computeCosineMoviesSimilarity).persist() # Now persist data on the storage, else use .cache() on above line
moviePairSimilaritiesData.sortByKey()
moviePairSimilaritiesData.saveAsTextFile(“sim-movies”) # Now extract the best similar movies
if (len(sys.argv) > 1): # hypothetical condition for a good similar movie based on parThreshold, occurThreshold
parThreshold = 0.97
occurThreshold = 1000 # get the input from command line
movieID = int(sys.argv[1]) # filter the movies based parThreshold, occurThreshold for the movie pair
filteredResultsData = moviePairSimilaritiesData.filter(lambda pairSim: \
(pairSim[0][0] == movieID or pairSim[0][1] == movieID) \
and pairSim[1][0] > parThreshold and pairSim[1][1] > occurThreshold) # Sort by quality score.
resultsData = filteredResultsData.map(lambda pairSim: (pairSim[1], pairSim[0])).sortByKey(ascending = False).take(25) print(“Top 25 similar movies for ” + movieDict[movieID])
for result in resultsData:
(simlr, pair) = result
# Display the similarity results
similarMovieID = pair[0]
if (similarMovieID == movieID):
similarMovieID = pair[1]
print(movieDict[similarMovieID] + “\tscore: ” + str(simlr[0]) + “\tstrength: ” + str(simlr[1]))
-
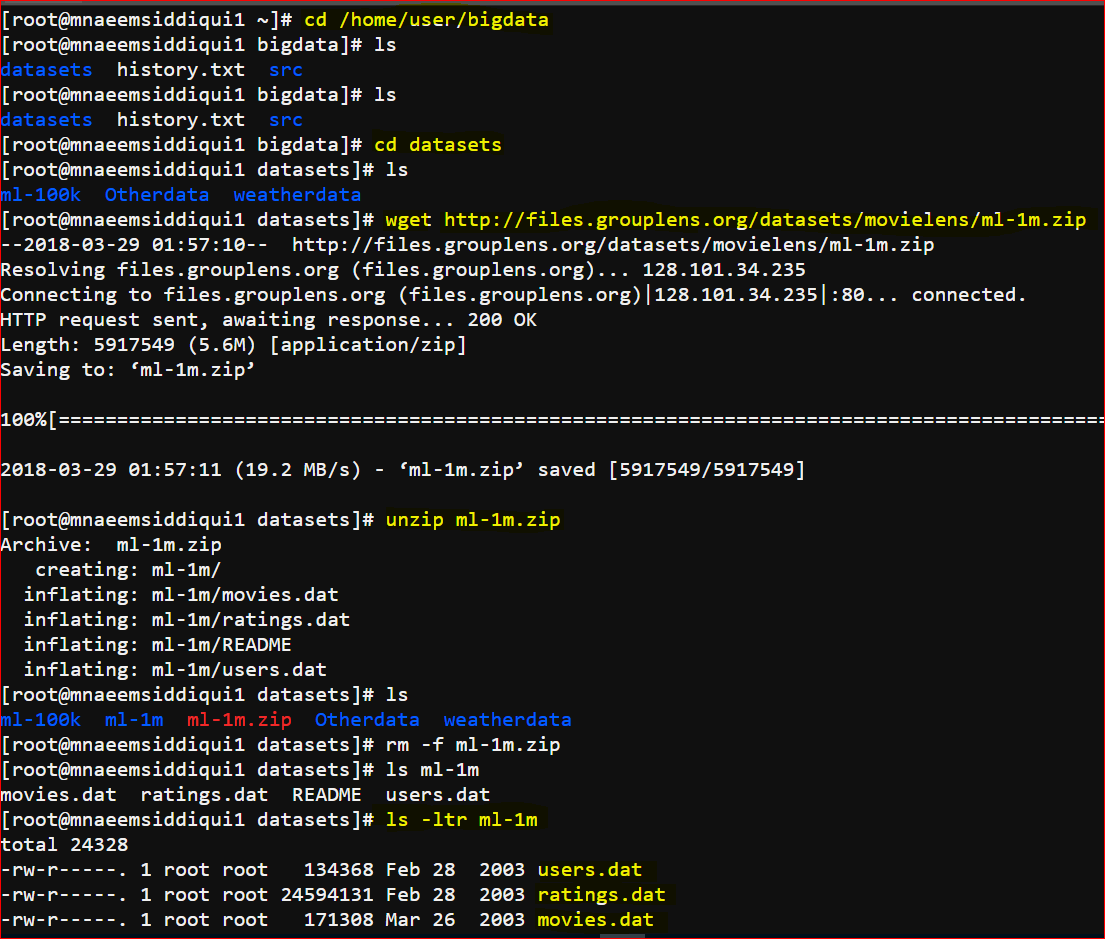
- Download the 1 million data-set from Movielens website – http://files.grouplens.org/datasets/movielens/ml-1m.zip
- Unzip the contents and store in folder – /home/user/bigdata/datasets/ml-1m
- Please note that this can be run on Amazon EMR too.
- The Output:
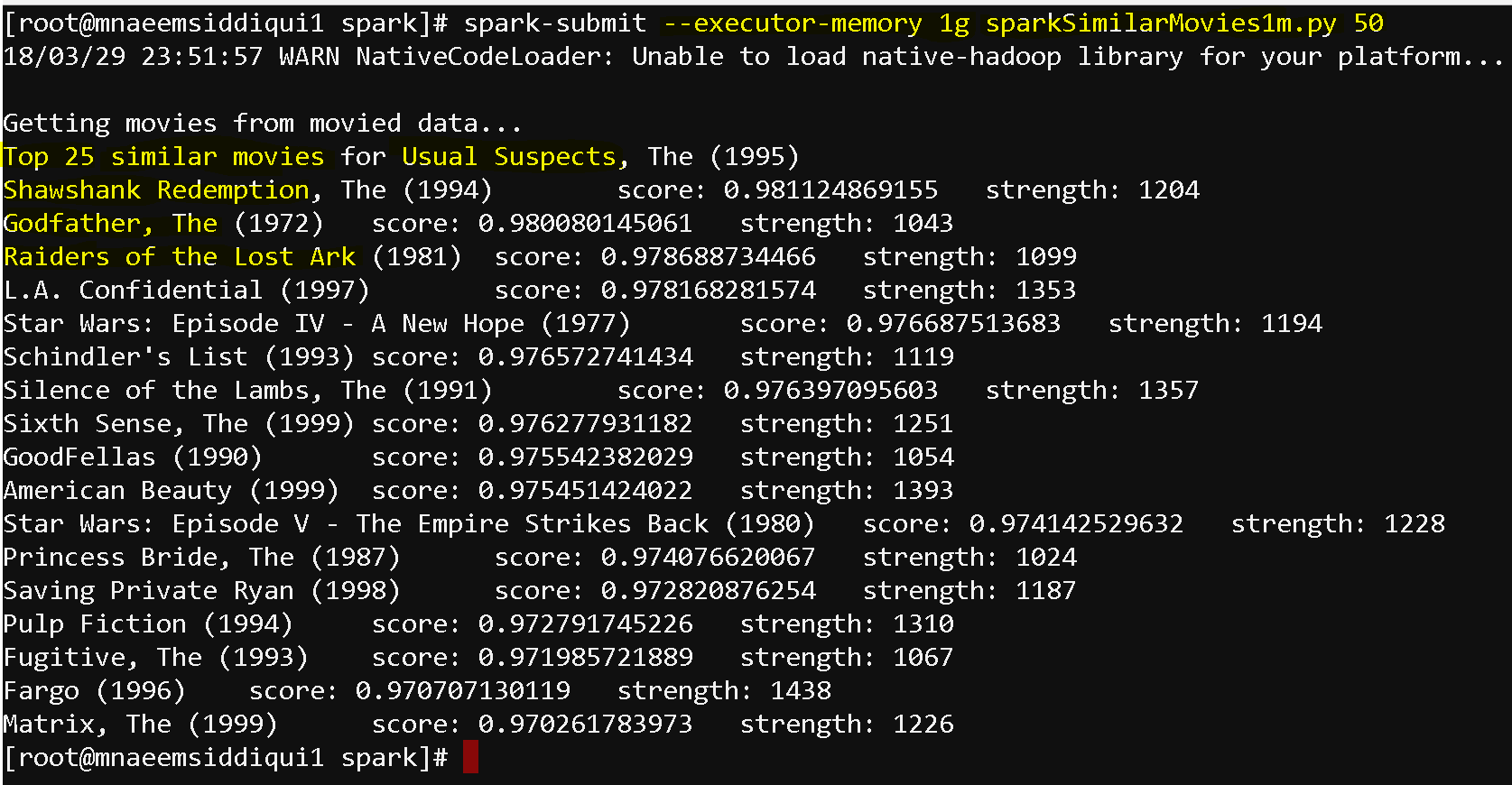
- Please see the output below with a data-set of 1 million ratings:
- spark-submit –executor-memory 1g sparkSimiarlMovies1m.py 260
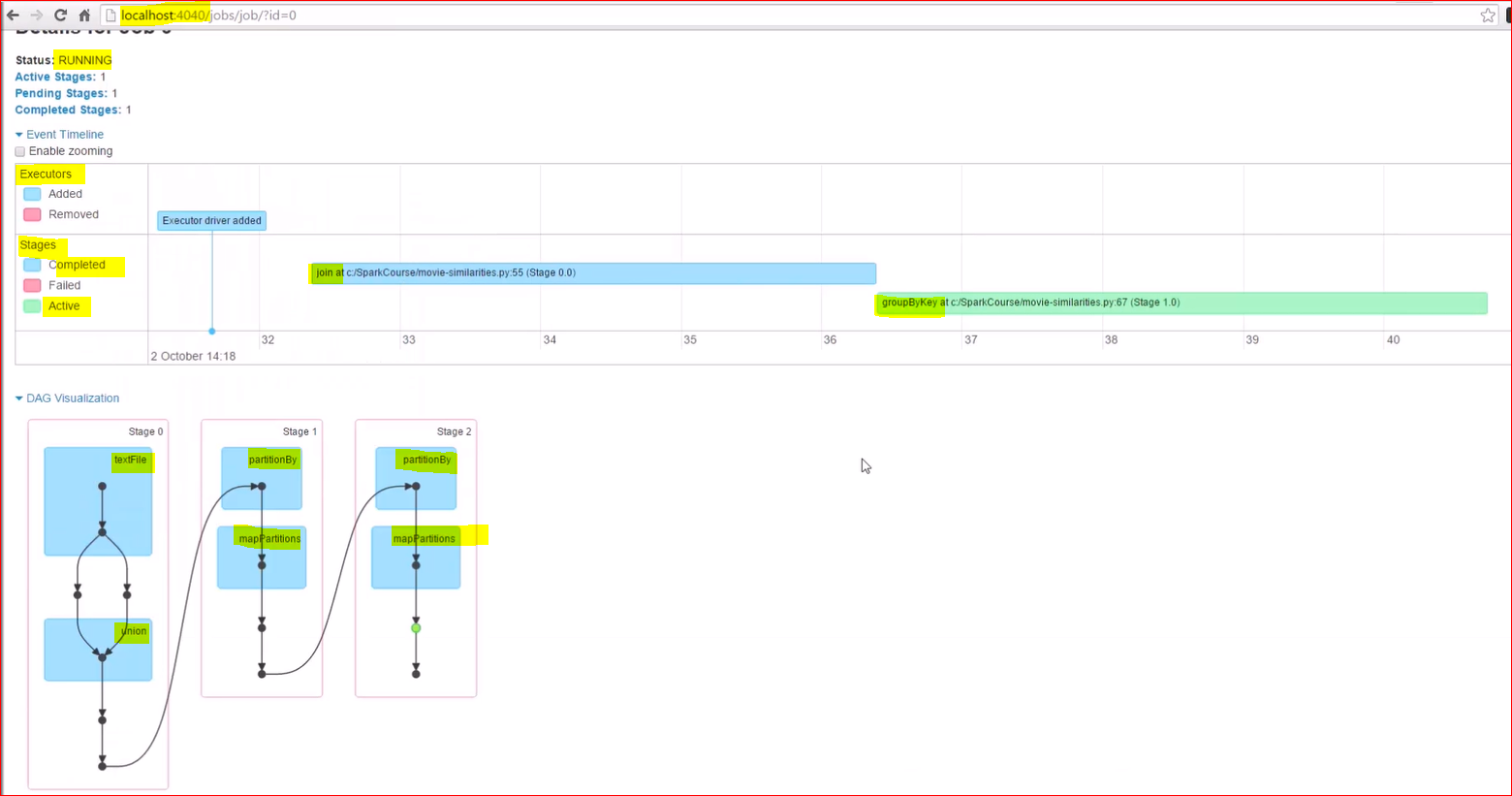
How to trouble shoot
- Spark UI can be opened at localhost:4040(default)
- The UI gives the list of executors, workflow, logs etc
- Other trouble shooting tips
- try increasing ‘executor-memory’ by default it is 512 MB. If the executers are hanging then its time to increase the memory like
- spark-submit –executor-memory 1g sparkSimilarMovies1m.py 50
- check the script logs while executing for any errors
- if some data is needed by all the executors then use broadcast variables
- while running on an EMR cluster you can store your files on s3 and the executors will reference the file from there.
- try increasing ‘executor-memory’ by default it is 512 MB. If the executers are hanging then its time to increase the memory like