- In this exercise we would like to solve the “Degree of separation” problem.
- In any social network, their is always a nth degree of separation between you and someone.
- E.g. between you and yourself there is a zero degree of separation,
- between you and your direct friend there is a first degree of separation
- between you and your friend of friend there is a second degree of separation
- based on the degree of separation, it is decided who can send you friend requests, or who can view your posts, who can tag you or so on and so forth
- We use an algorithm called as “Breadth first search”
- Lets try to understand he snapshot below:
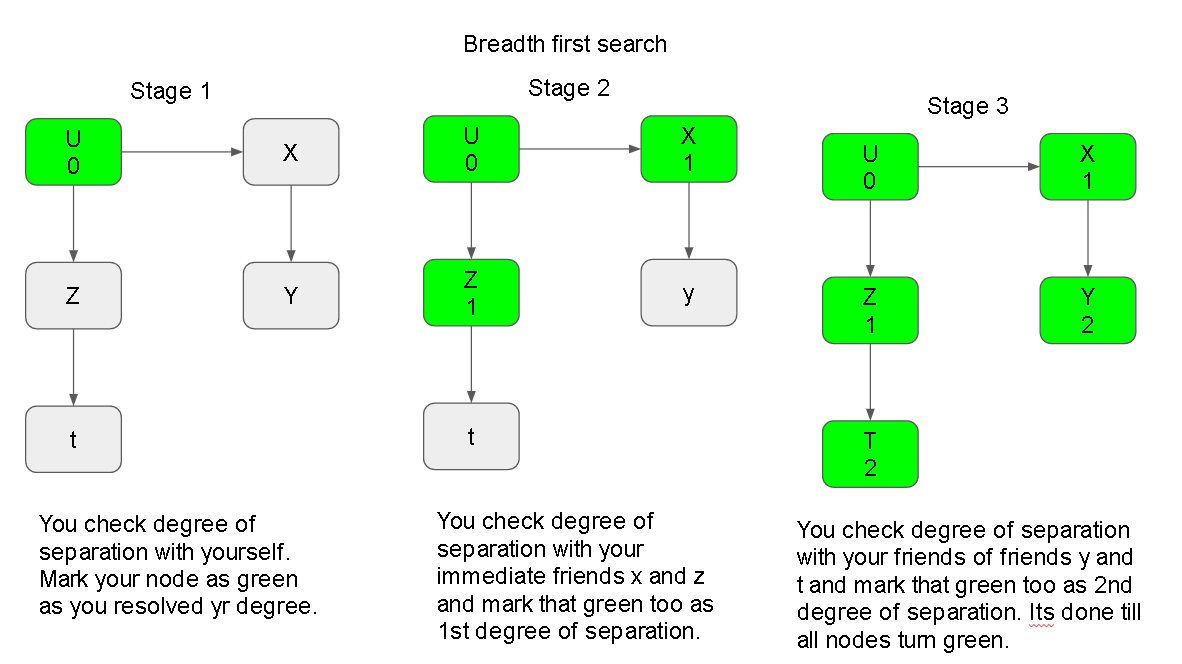
- We need to encapsulate this algorithm in our code to detect the degree of separation.
- If we revisit “marvel-network.txt” file, we see that the first field is the heroID and rest of the columns are the heroIds of the hero with whom it has worked with. we will have to map these lines to hold a tuple something like this:
- (10034, (10004, 45671, 33421, 10023), 9999, grey)
- 100034 is the heroId, 10004, 45671, 33421, 10023 are the heroIds of the heros with whom it has worked with, 9999 is the infinity distance(because we would never need a 9999 degree of separation) and finally grey is the initial color for the node.
- we will process this tuple so that the separation value is set and once it is convert the color to green. We will repeat this process till all nodes are processed.
- a python function like this can handle this scenario as below:
-
def processHeroNetwork(line):
fields = line.split()
heroId = int(fields[0])
networks = []
for field in fields[1:]:
networks.append(int(field))
color = ‘white’
if (heroId == startingField):
color = “green”
dist = 9999
return (heroId, (networks), dist, color)
-
- Now that we have a tuple of info as per the design we need, we will apply the mapper and reducer function on the data
- Mapper will will create a new node for each gray node with distance incremented by 1 and no connections, also will convert the gray node to green once the node is processed
- Reducer will combine the nodes/networks of a heroID and preserve the shortest node and the node color as green and
- we use concept of accumulator to create a shared variable across cluster – sc.accumulator(0)
- we iterate and increment the accumulator counter till the heroId is hit and is greater than 1
- Lets now jump into the code and see how the accumulator works.
- Download file – https://testbucket786786.s3.amazonaws.com/spark/sparkDegreeOfSeparation.py
- Here is the code :
-
# first import SparkConf, SparkContext
from pyspark import SparkConf, SparkContext # setup SparkConf, SparkContext
sConf = SparkConf().setMaster(“local”).setAppName(“SparkDegreeofSeparationApp”)
sContext = SparkContext(conf = sConf) # setup the accumulator
hitCounter = sContext.accumulator(0) def processHeroNetworks(line):
fields = line.split()
heroID = int(fields[0])
networks = []
for hID in fields[1:]:
networks.append(int(hID)) clr = ‘WHITE’
dist = 9999 if (heroID == startingHeroID):
clr = ‘GRAY’
dist = 0 return (heroID, (networks, dist, clr)) def loadData():
dataFile = sc.textFile(“/home/user/bigdata/datasets/Otherdata/marvel-heroes.txt”)
return dataFile.map(processHeroNetworks) def execMapper(heroNode):#get the tuple data in the form (heroID, (networks, dist, clr)) extract the heroId and network data
heroID = heroNode[0]
networkData = heroNode[1]
networks = networkData[0]
dist = danetworkDatata[1]
clr = networkData[2]results = []
# expand heroNode if required, by checking if the target HeroId is hit or not
if (clr == ‘GRAY’):for connection in networks:
newheroID = connection
newdist = dist + 1
newclr = ‘GRAY’
if (targetHeroID == connection):
heroHitCtr.add(1)newEntry = (newheroID, ([], newdist, newclr))
# preserve the node
results.append(newEntry)# set color black for that node if all the nodes are executed
clr = ‘BLACK’
# save input heroID
results.append( (heroID, (networks, dist, clr)) )
return resultsdef execReducer(heroData1, heroData2):
edges1 = heroData1[0]
edges2 = heroData2[0]dist1 = heroData1[1]
dist2 = heroData2[1]
clr1 = heroData1[2]
clr2 = heroData2[2]
dist = 9999
clr = clr1
edges = []
# preserve edges
if (len(edges1) > 0):
edges.extend(edges1)
if (len(edges2) > 0):
edges.extend(edges2)# preserve min distance
if (dist1 < dist):dist = dist1
if (dist2 < dist):
dist = dist2
# Preserve darkest color
if (clr1 == ‘WHITE’ and (clr2 == ‘GRAY’ or clr2 == ‘BLACK’)):clr = clr2
if (clr1 == ‘GRAY’ and clr2 == ‘BLACK’):
clr = clr2
if (clr2 == ‘WHITE’ and (clr1 == ‘GRAY’ or clr1 == ‘BLACK’)):
clr = clr1
if (clr2 == ‘GRAY’ and clr1 == ‘BLACK’):
clr = clr1
return (edges, dist, clr)
# The characters we wish to find the degree of separation between:
startingHeroID = 2399 # “HAWK”
targetHeroID = 12930 # “MARVELS 3” # load the marvel-network.txt data file as per the tuple structure we want
rddToIterate = loadData() # assuming that no one would be as far as 25th degree of separation thats why range(0,25)
for ctr in range(0, 25):print(“Searching target in iteration# ” + str(ctr+1))
# execute the mapper to create new vertices’s and and update the accumulator as we encounter gray node
mappedRDD = rddToIterate.flatMap(execMapper)
# count function here is an action thus updating the RDD
print(“Processing ” + str(mappedRDD.count()) + ” values.”)
#if the target is found then prompt the message
if (heroHitCtr.value > 0):print(“What a catch! Got the target at ” + str(heroHitCtr.value) + ” degree of separation.”)
break
# execute the reduce to combine all data and preserve the darkest color plus shortest distance
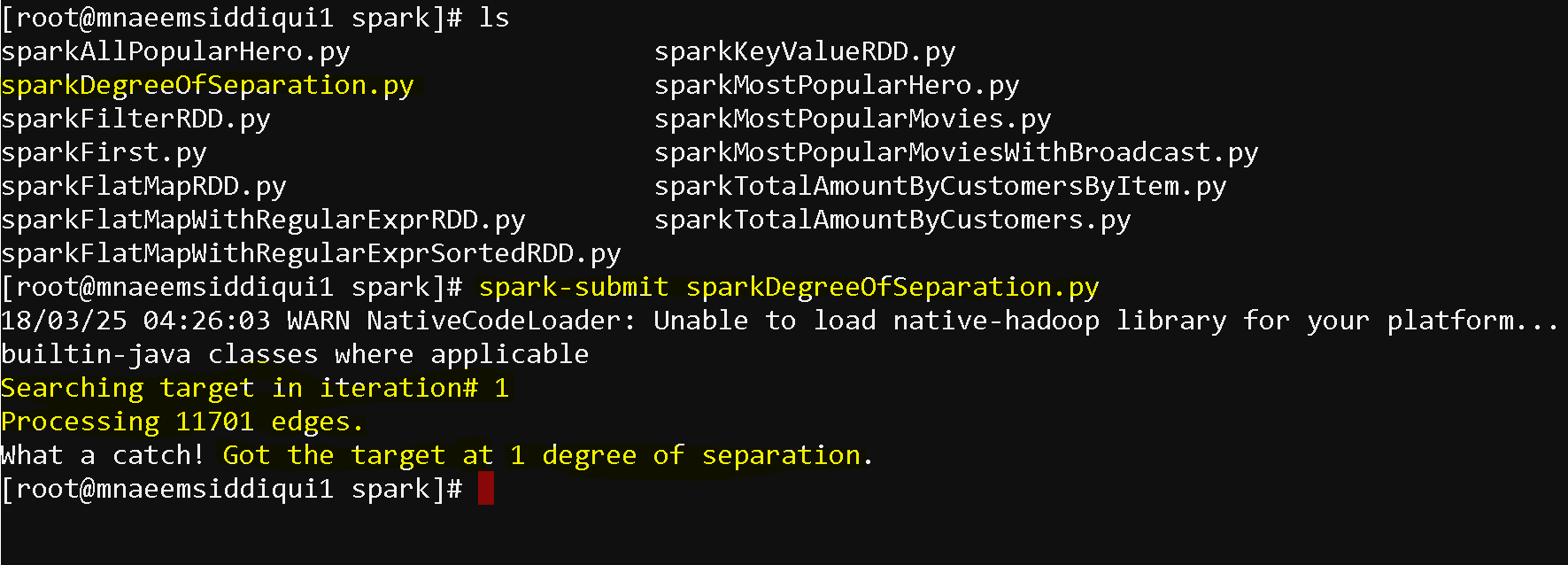
rddToIterate = mappedRDD.reduceByKey(execReducer) - and here is the output :
- We got the result – HAWK has a 1 degree of separation from MARVELS 3
Apache Spark – A Deep Dive – Series 7 of N – Analysis a Super Heroes Social Network Graph – Degree of Separation
