Notes:
- The data set for this exercise is from National Centers for Environmental Information (NCEI) at http://www.ncdc.noaa.gov/data-access/quick-links
- Click the link Global Historical Climatology Network-Daily (GHCN-D)
- Click the GHCN-Daily FTP Access link
- Click the by_year folder link.
- and download 2017 year data – ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/daily/by_year/2017.csv.gz
- Extract the .gz file to a location – say : D:\dumps\BigData\weatherdata\2017.csv
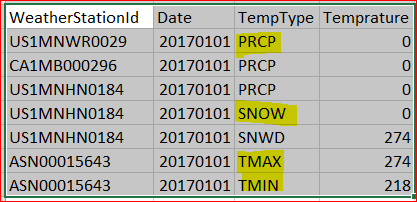
- The file structure is like this – (the actual files does not has a header, the snapshot is showing header for explanation purpose –
- 1st Column is weather station id, 2nd column is date, 3rd column is temperature type e.g TMAX(max temperature) , TMIN (min temperature), SNOW ( snow) or PRCP ( Precipitation ) etc and 4th column is trmpreture in Celcius.
Filter an RDD:
- We use filter function to filter data from data set, if the filter expression returns True then only those rows are held in the data set otherwise scarped.
- rdd.Filter(lambda x: x[2]=’TMIN’) – will filter rows which have TMIN
- rdd.Filter(lambda x: x[2]=’TMAX’) – will filter rows which have TMAX
- The code is similar to last exercise using reduceByKey to get min temp of the year of TMIN type.
- Here is the output –
- Here is the download link –
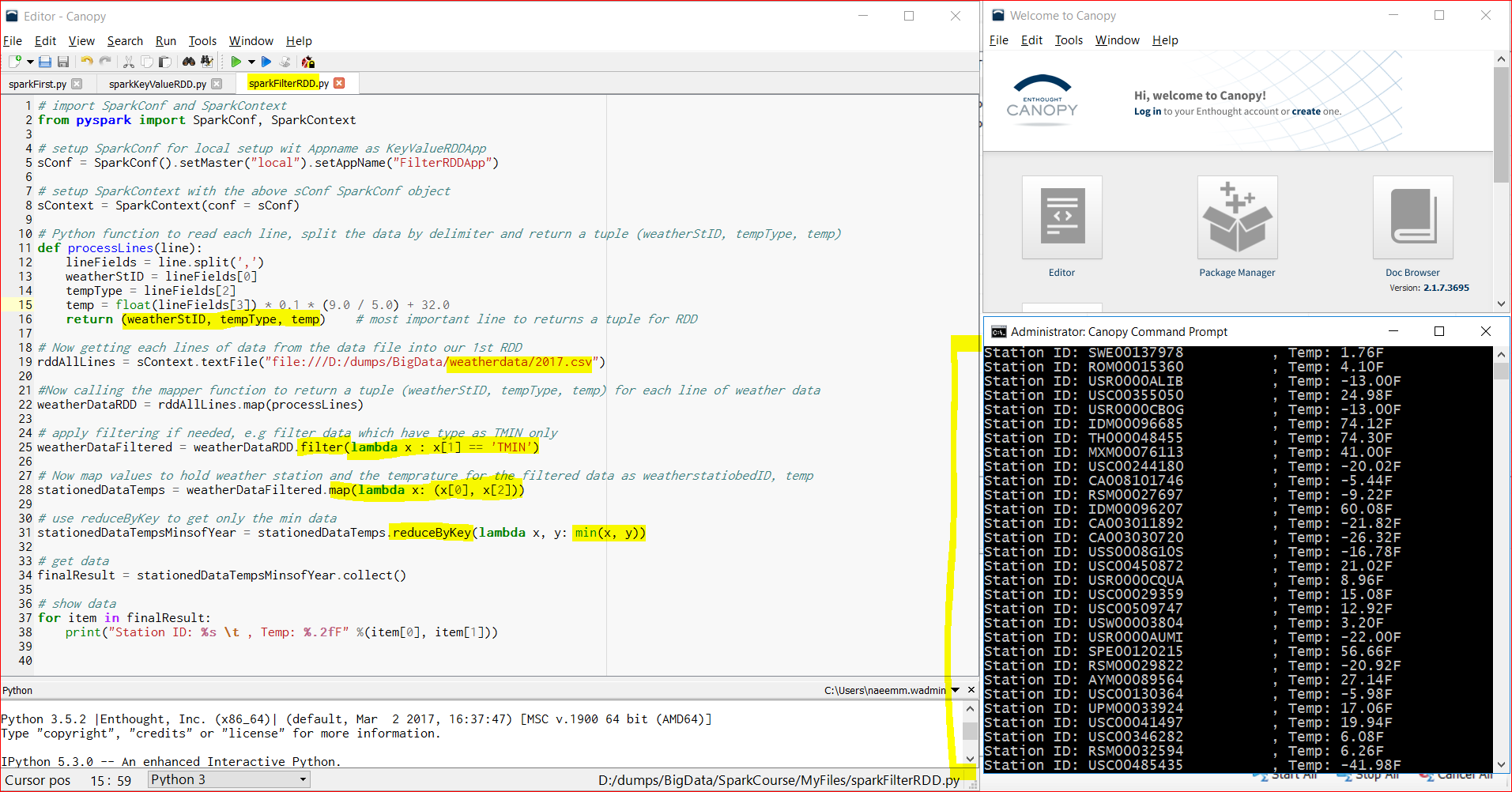
- Here is the code –
-
# import SparkConf and SparkContext from pyspark import SparkConf, SparkContext # setup SparkConf for local setup wit Appname as KeyValueRDDApp sConf = SparkConf().setMaster(“local”).setAppName(“FilterRDDApp”) # setup SparkContext with the above sConf SparkConf object sContext = SparkContext(conf = sConf) # Python function to read each line, split the data by delimiter and return a tuple (weatherStID, tempType, temp) def processLines(line): lineFields = line.split(‘,’) weatherStID = lineFields[0] tempType = lineFields[2] temp = float(lineFields[3]) * 0.1 * (9.0 / 5.0) + 32.0 return (weatherStID, tempType, temp) # most important line to returns a tuple for RDD # Now getting each lines of data from the data file into our 1st RDD rddAllLines = sContext.textFile(“file:///D:/dumps/BigData/weatherdata/2017.csv”) #Now calling the mapper function to return a tuple (weatherStID, tempType, temp) for each line of weather data weatherDataRDD = rddAllLines.map(processLines) # apply filtering if needed, e.g filter data which have type as TMIN only weatherDataFiltered = weatherDataRDD.filter(lambda x : x[1] == ‘TMIN’) # Now map values to hold weather station and the temprature for the filtered data as weatherstatiobedID, temp stationedDataTemps = weatherDataFiltered.map(lambda x: (x[0], x[2])) # use reduceByKey to get only the min data stationedDataTempsMinsofYear = stationedDataTemps.reduceByKey(lambda x, y: min(x, y)) # get data finalResult = stationedDataTempsMinsofYear.collect() # show data for item in finalResult: print(“Station ID: %s \t , Temp: %.2fF” %(item[0], item[1]))
-