- Why Flink:
- more scalable than Storm upto more than 1000s of nodes( massive scale)
- more fault tolerant than Storm
- maintain “state snapshots” to guarantee exactly once processing
- In similarity, it is also based on event based streaming like Storm
- Flink Vs Spark Streaming Vs Storm:
- Faster than Storm
- real time streaming like Storm
- event based like storm and maintains windowing
- exactly once guarantee is good for financial applications
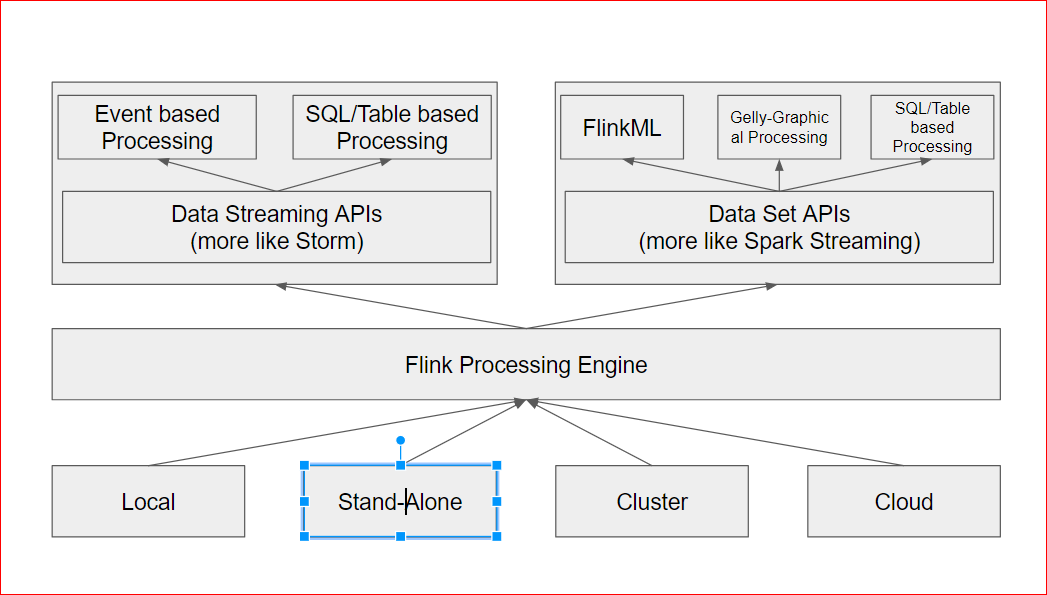
- Flink Architecture:
- Flink can sit on the top of a local or standalone or a cluster based Hadoop system or even on the cloud on AWS or Google Cloud
- Flink has 2 distinct set of APOs – Data Streaming APIs( more like Storm) as well as Data Set APIs( more like Spark Streaming)
- In its each universe –
- Data Streaming APIs support Event based processing as well as SQL/Table based processing.
- Data Set APIs support FlinkML, Gelly and SQL/Table based processing
- Connectors for Flink – HDFS, Kafka, Cassandra, RabbitMQ, Redis, Elastic search, NIFI etc
- Lets play with Flink:
- Login to the console using maria_dev credentials and elevate to root permissions.
- Download Apache Flink from apache.flink.org. Download using this link – wget https://archive.apache.org/dist/flink/flink-1.2.0/flink-1.2.0-bin-hadoop27-scala_2.10.tgz
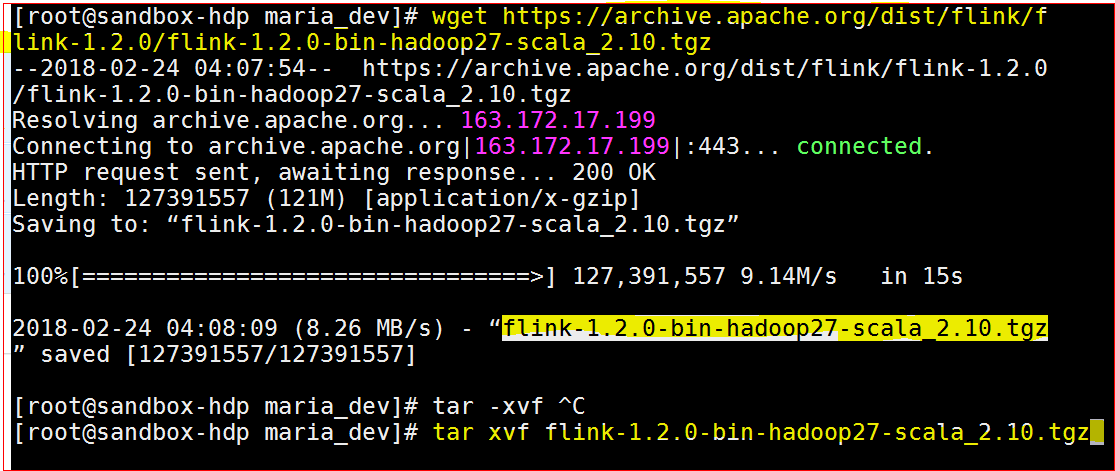
- Unzip the downloadable – tar xvf flink-1.2.0-bin-hadoop27-scala_2.10.tgz
- Move to the flink folder – cd flink-1.2.0
- Now first lets configure the config files – cd conf
- Edit – nano flink-conf.yaml
- jobmanager.web.port: 8081 to jobmanager.web.port: 8082
- Now lets start flink – go to flink’s bin folder and run
- ./start-local.sh
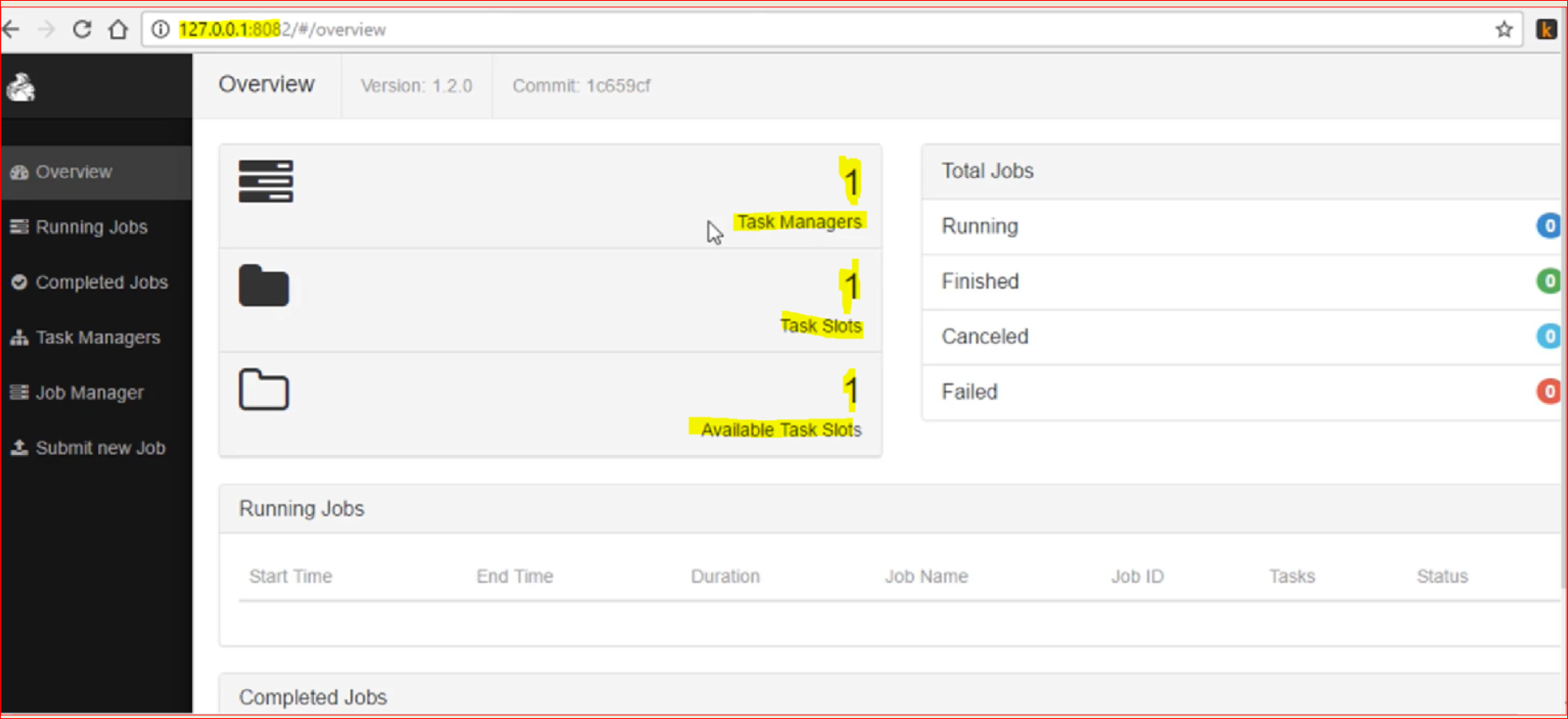
- Now lets open the Flink WEb UI – http://127.0.0.1:8082
- Now lets run one example from GitHub location – wget https://raw.githubusercontent.com/apache/flink/master/flink-examples/flink-examples-streaming/src/main/scala/org/apache/flink/streaming/scala/examples/socket/SocketWindowWordCount.scala
- here is the heart of the code.
- You first get the streaming env –
- // get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
- // get the execution environment
- Then you process and transform the data –
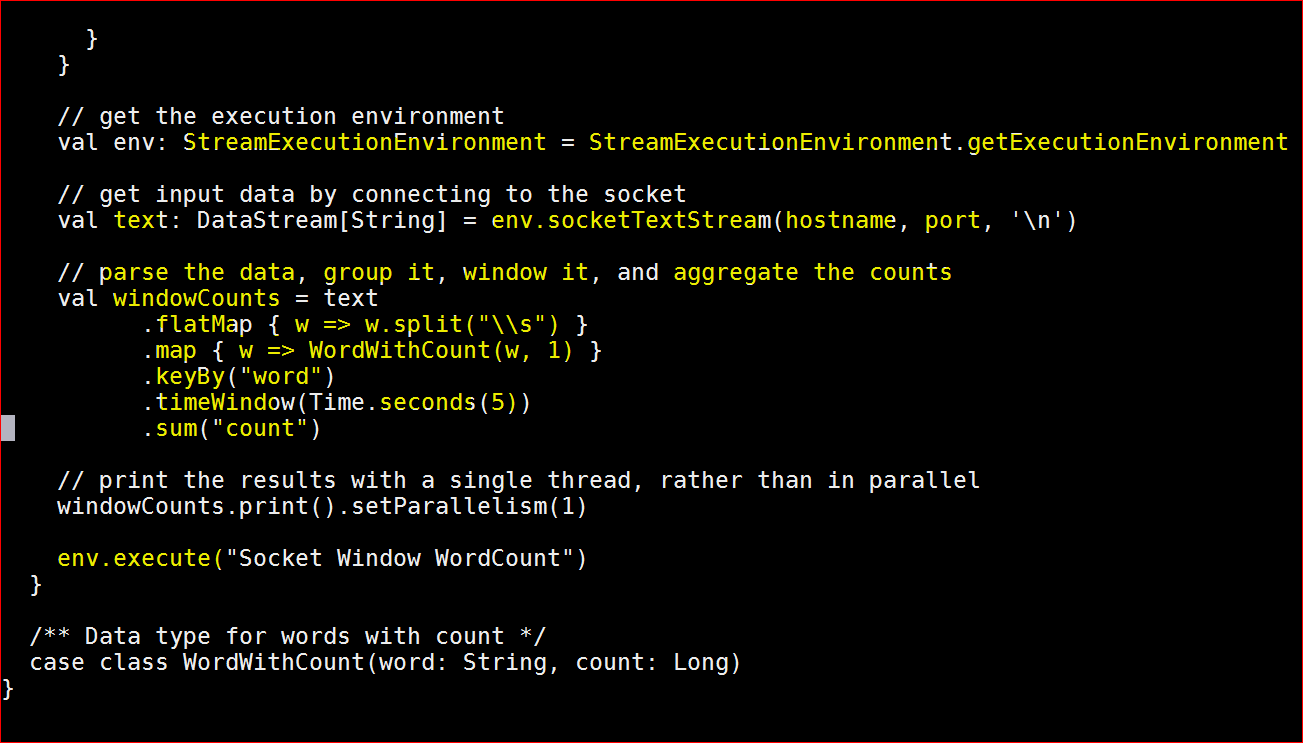
- // parse the data, group it, window it, and aggregate the counts
val windowCounts = text
.flatMap { w => w.split(“\\s”) }
.map { w => WordWithCount(w, 1) }
.keyBy(“word”)
.timeWindow(Time.seconds(5))
.sum(“count”)
- // parse the data, group it, window it, and aggregate the counts
- You first get the streaming env –
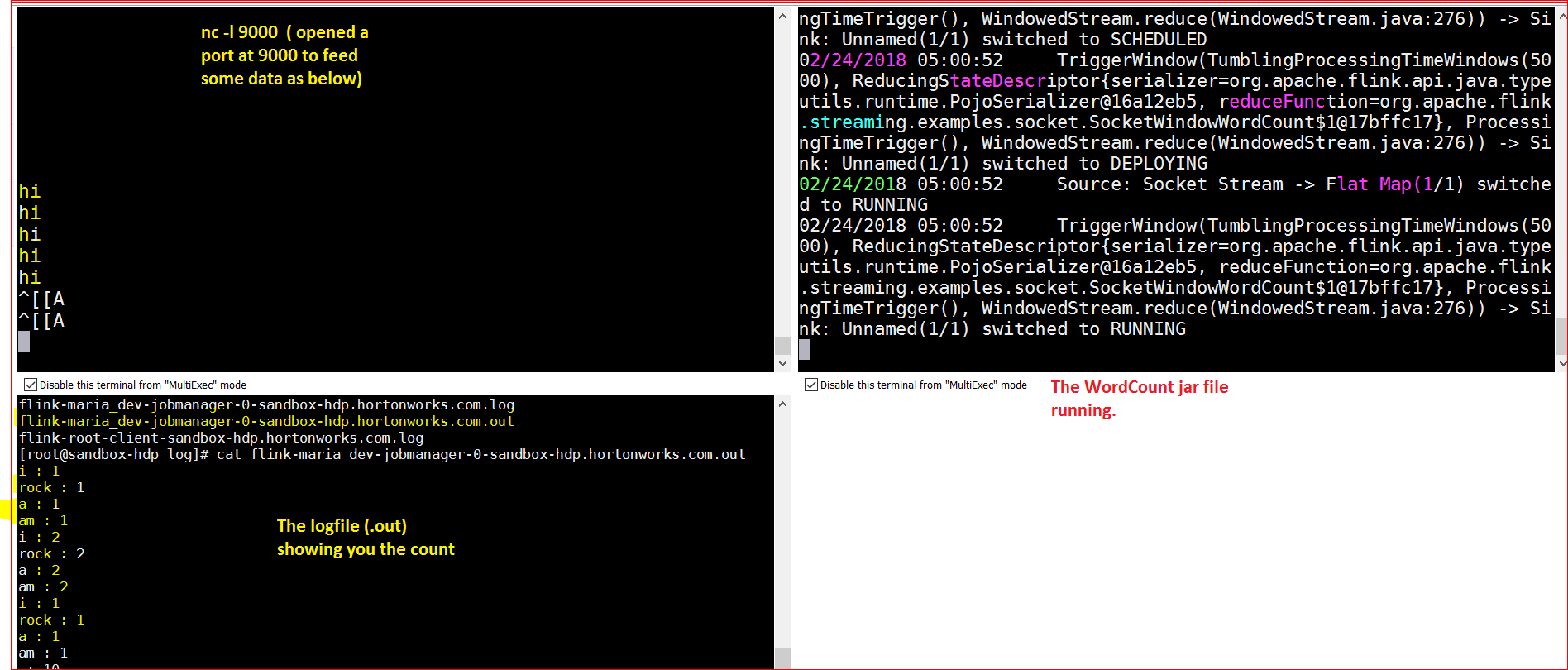
- Now lets open up a port and listen on port 9000 – nc -l 9000
- Now run the example –
- go to /home/maria_dev/cd flink-1.2.0
- now run – ./bin/flink run examples/streaming/SocketWindowWordCount.jar –port 9000
- Output –
Apache Flink – Highly Scalable Streaming Engine
