
Apache Storm Vs Apache Spark Streaming:
- Apache Storm – real time up to a sub-second level and is event based
- Apache Spark Streaming – real time only up to a second level and is micro-batch processing based.
Apache Storm Architecture and terminologies:
- Its used very specific terminologies – spout and bolt
- Spout is the stream receiver and bolt is the stream processor.
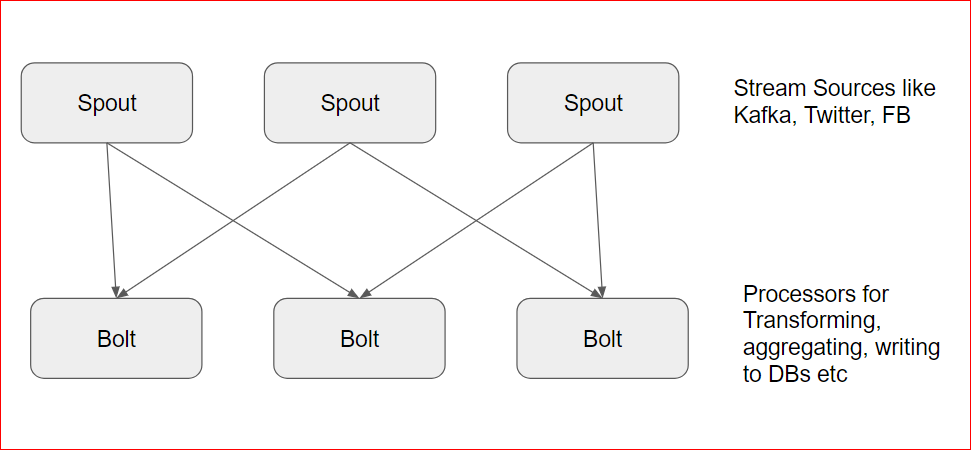
- Exposes 2 kinds of APIs – Storm Core and Trident and works very nicely with Kafka.
- Unlike Spark Streaming it provides something called “tumbling window”(they don’t overlap and e.g. if we have 3 separate windows of 5s then they are 3 different 5 sec windows ) which is unlike “sliding window”(sliding windows can overlap)
Lets play with Apache Storm:
- Apache Storm comes pre-installed on Hortonworks so lets start Storm and Kafka.
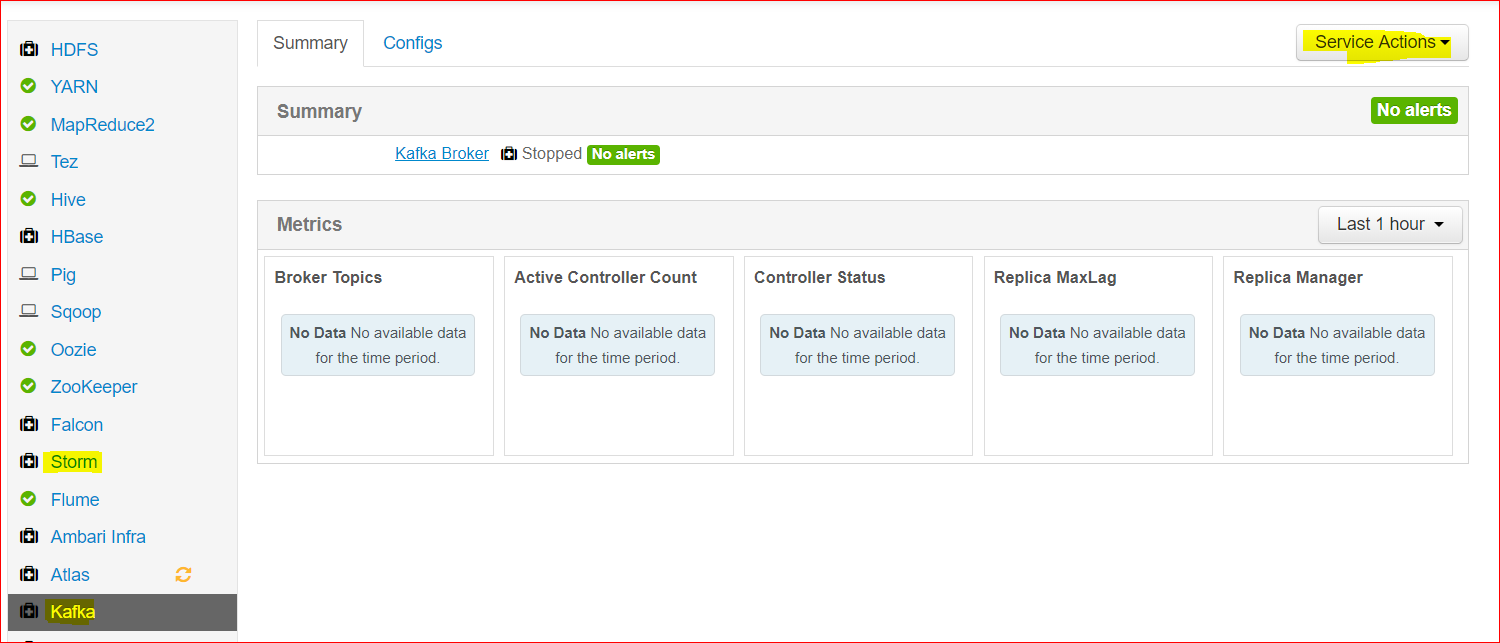
- Now lets login to the Ambari Console.
- This files take a stream of sentences and counts the word by updating a map.
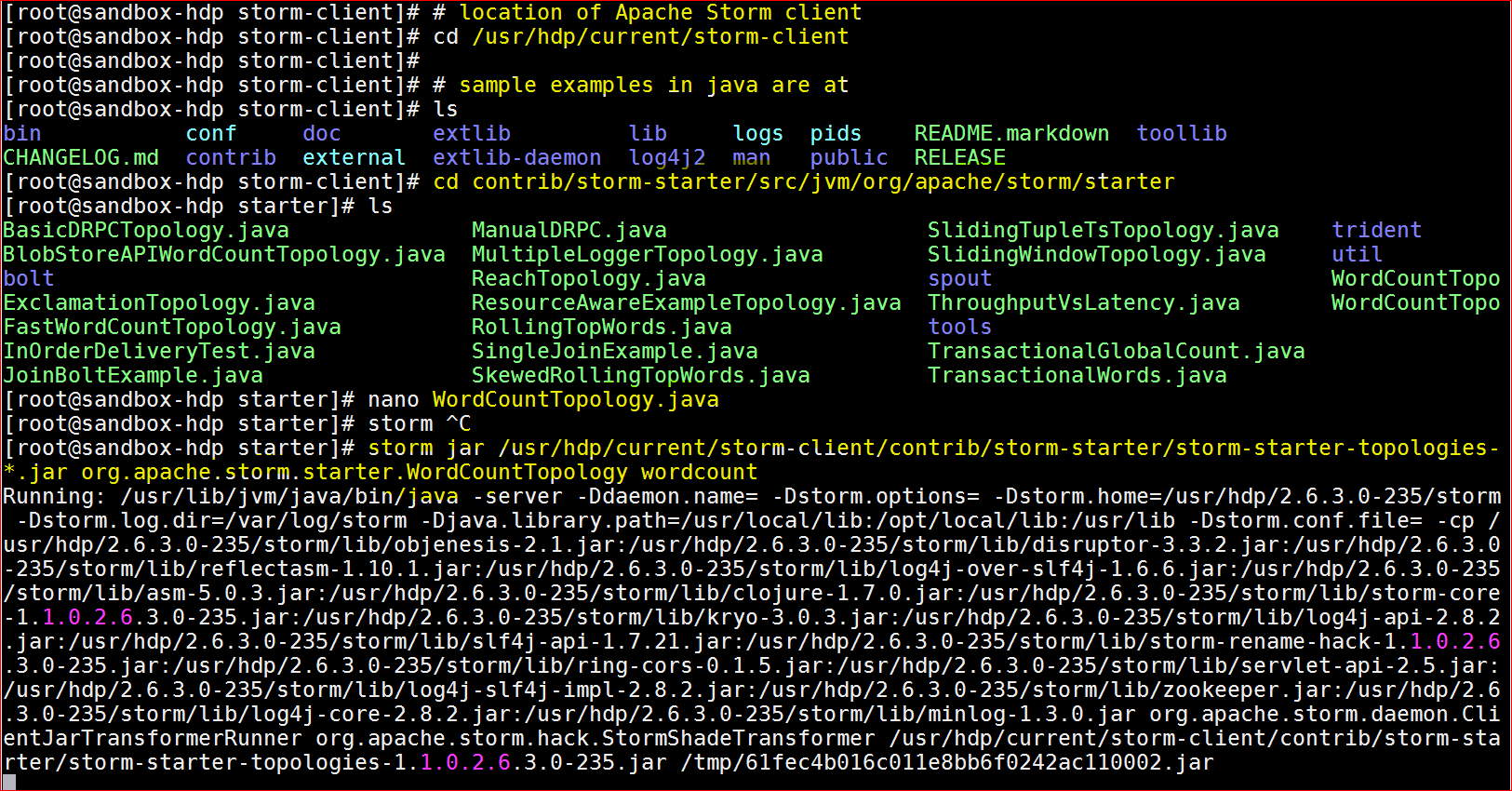
- location of Apache Storm client : cd /usr/hdp/current/storm-client
- Sample Examples location – cd contrib/storm-starter/src/jvm/org/apache/storm/starter
- lets refer to this file – https://testbucket786786.s3.amazonaws.com/WordCountTopology.java
- Lets run the file – storm jar /usr/hdp/current/storm-client/contrib/storm-starter/storm-starter-topologies-*.jar org.apache.storm.starter.WordCountTopology wordcount
- lets it run and lets go to the browser to see the Storm UI(rungs on port 8744) – http://127.0.0.1:8744
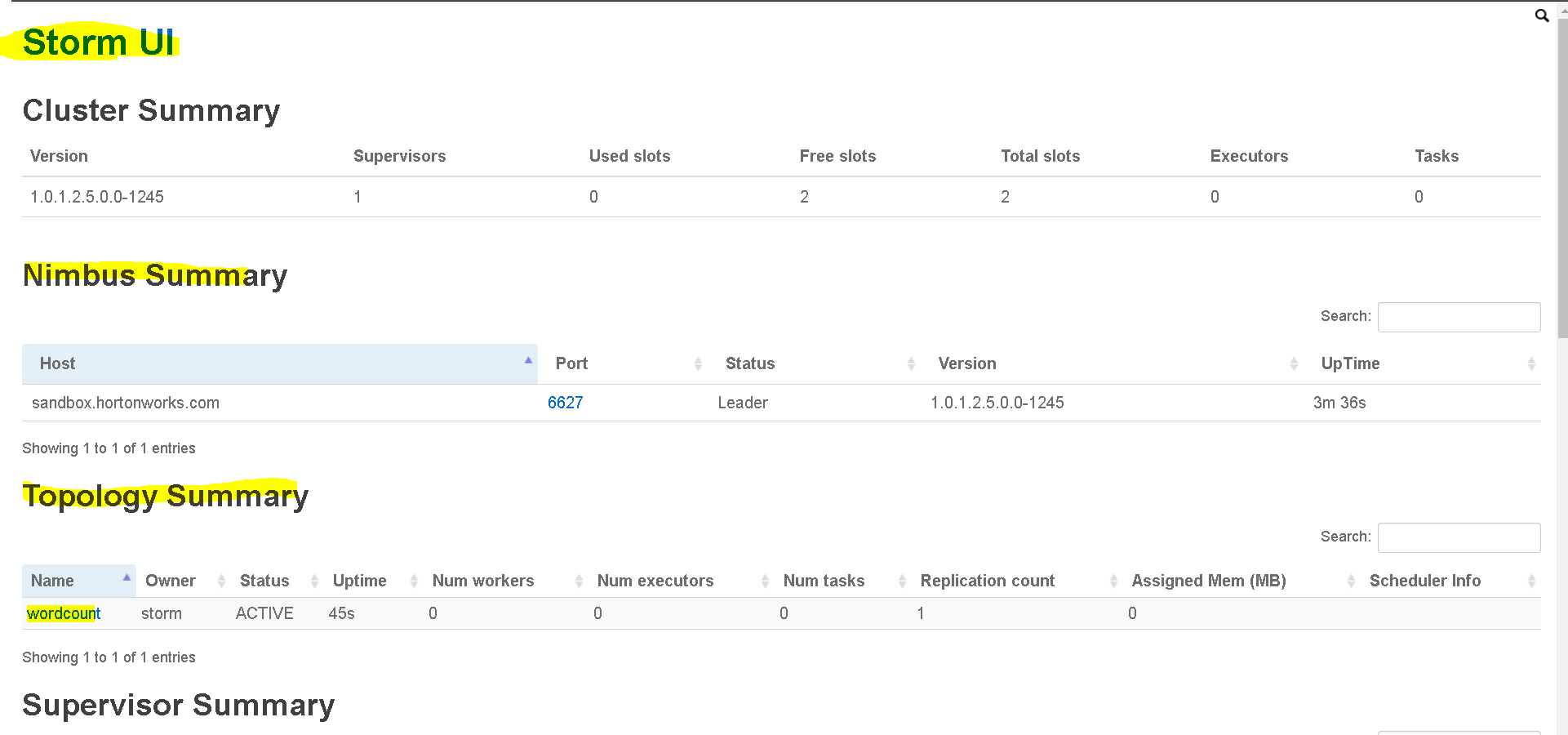
- Now lets see if what dis it process in WordTopology.
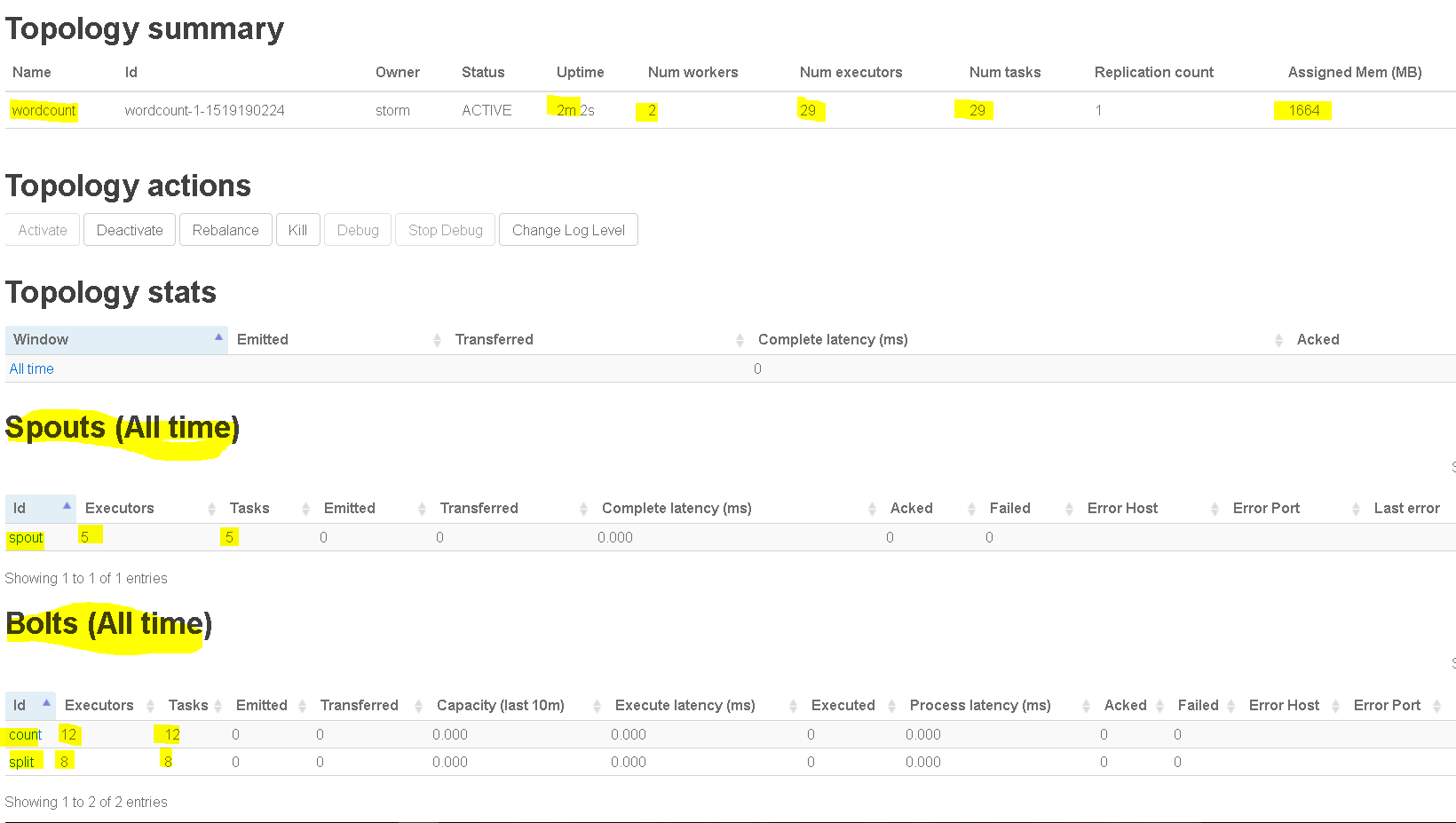
- Let check the logs now at : cd /usr/hdp/current/storm-client/logs/workers-artifacts
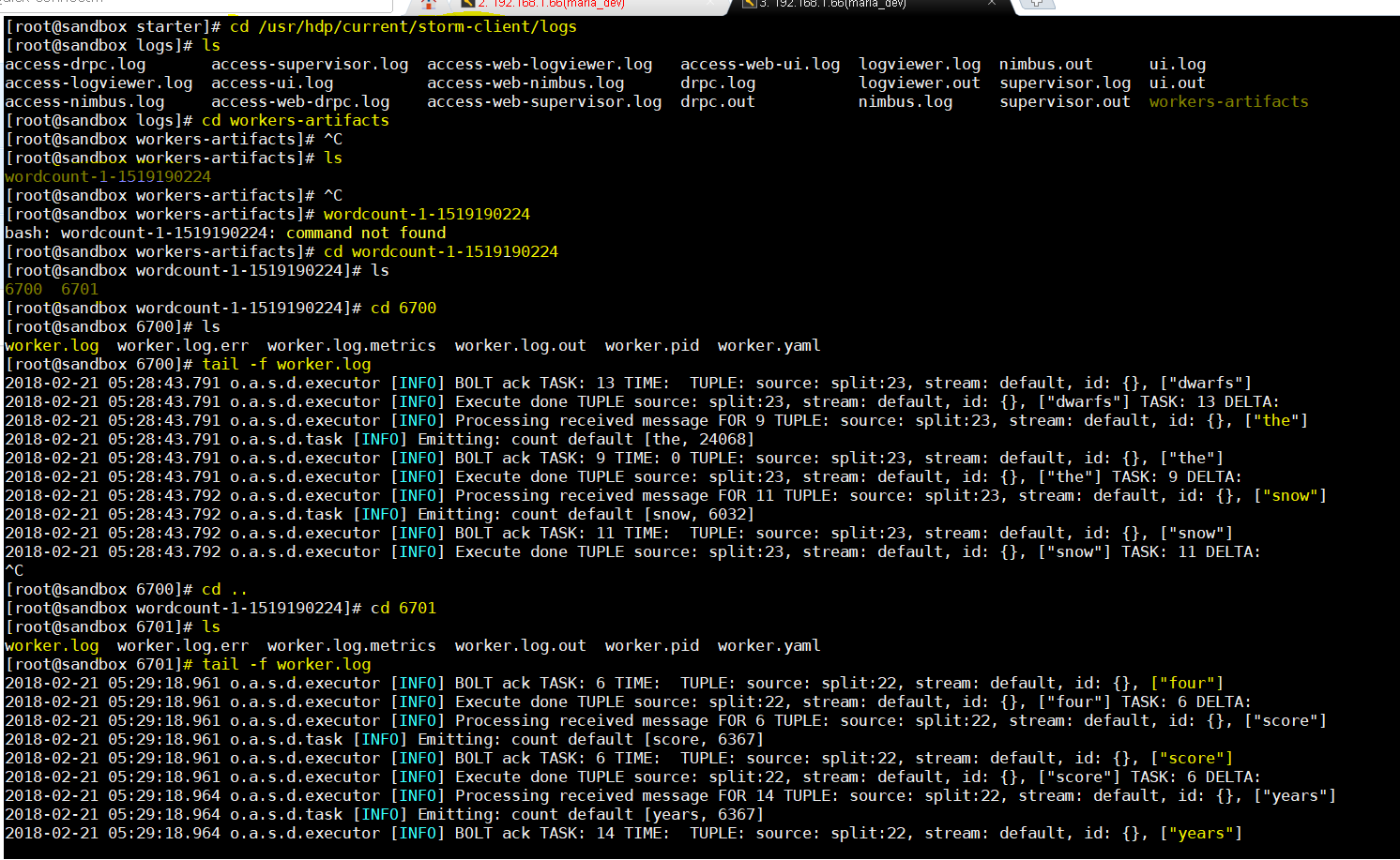
- In the exercise the data was dumped to the log. We could have even written this to HDFS or some other source